gc
gc
垃圾回收要干的事就是将不再使用的对象内存释放,腾出空间给其它对象使用。就这么简单的一句描述但它实现起来却非常不简单,垃圾回收的发展历史已经有了几十年,最早在上世纪 60 年代的 Lisp 语言就首次采用了垃圾回收机制,我们所熟知的 Python,Objective-C,其主要的 GC 机制就是引用计数,Java,C#采用的是分代回收。在今天来看垃圾回收,从回收算法来看,可以大致分为下面几个大类:
- 引用计数:让每一个对象记录自身被引用了多少次,当计数为 0 时,就将其回收
- 标记清除:将活动的对象做标记,将未标记的对象进行回收
- 复制算法:将活动对象复制到新的内存中,将旧内存中的所有对象全部回收,达到回收垃圾目的
- 标记压缩:标记清除的升级版,回收时将活动对象移动到堆的头部,方便管理
从应用方式来看,可以分为下面几个大类:
- 全局回收:一次直接回收所有的垃圾
- 分代回收:根据对象的存活时间分成不同的代,然后采用不同的回收算法
- 增量回收:每一次只进行局部的垃圾回收
提示
前往The Journey of Go's Garbage Collector阅读英文原文,了解更多有关 Go 垃圾回收的历史
在刚发布时,Go 的垃圾回收机制十分简陋,只有简单的标记清除算法,垃圾回收所造成的 STW(Stop The World,指因垃圾回收暂停整个程序)高达几秒甚至更久。意识到这一问题的 Go 团队变开始着手改进垃圾回收算法,在 go1.0 到 go1.8 版本之间,他们先后尝试过很多设想
- 读屏障并发复制 GC:读屏障的开销有很多不确定性,这种方案被取消了
- 面向请求的收集器(ROC):需要时刻开启写屏障,拖累运行速度,拉低了编译时间
- 分代回收:分代回收在 go 中的效率并不高,因为 go 的编译器会倾向于将新对象分配到栈上,长期存在的对象分配到堆上,所以新生代对象大多数会被栈直接回收。
- 无写屏障的卡片标记:通过哈希散列成本来替代写屏障的成本,需要硬件配合
最后 Go 团队还是选择了三色并发标记+写屏障的组合,并且在后续的版本中不断的改进和优化,这种做法也一直沿用到现在,下面一组图展示了从 go1.4 至 go1.9 的 GC 延时变化。
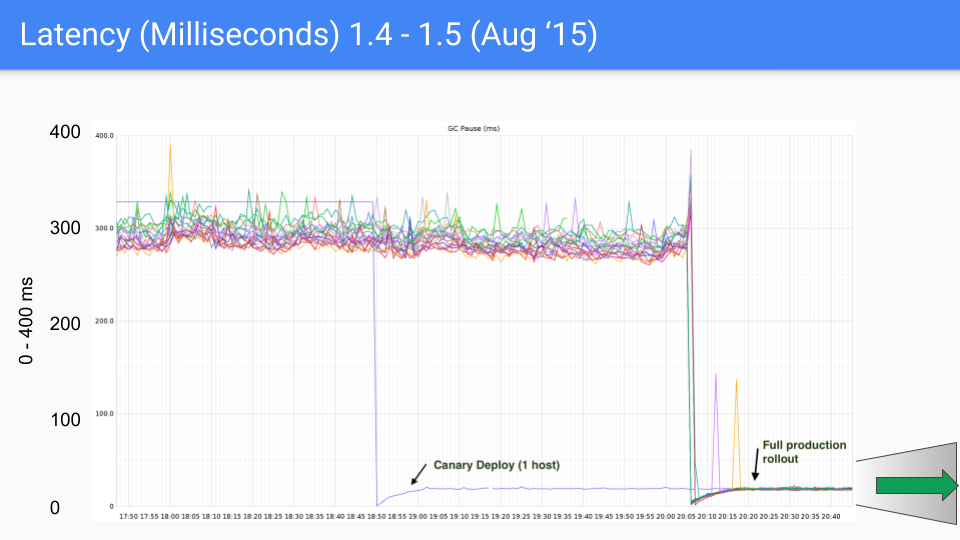
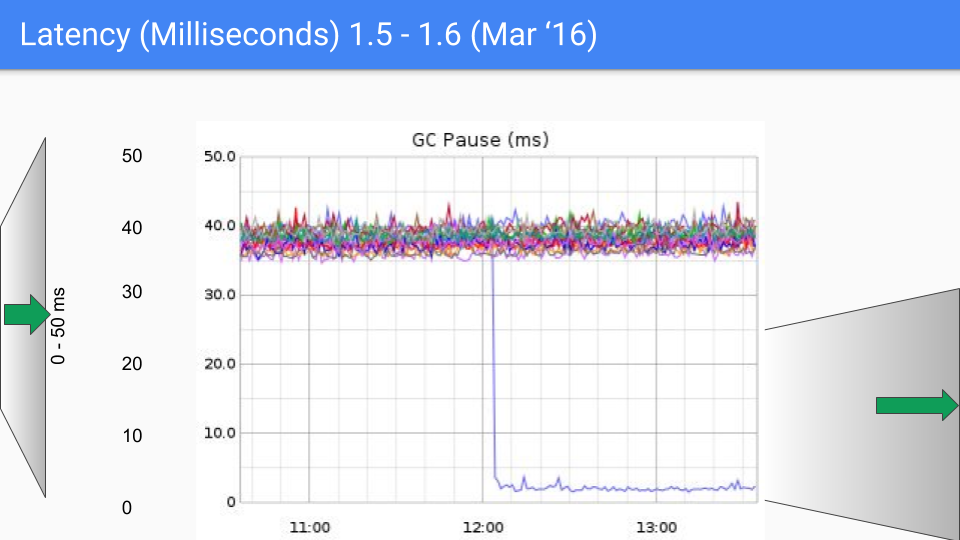
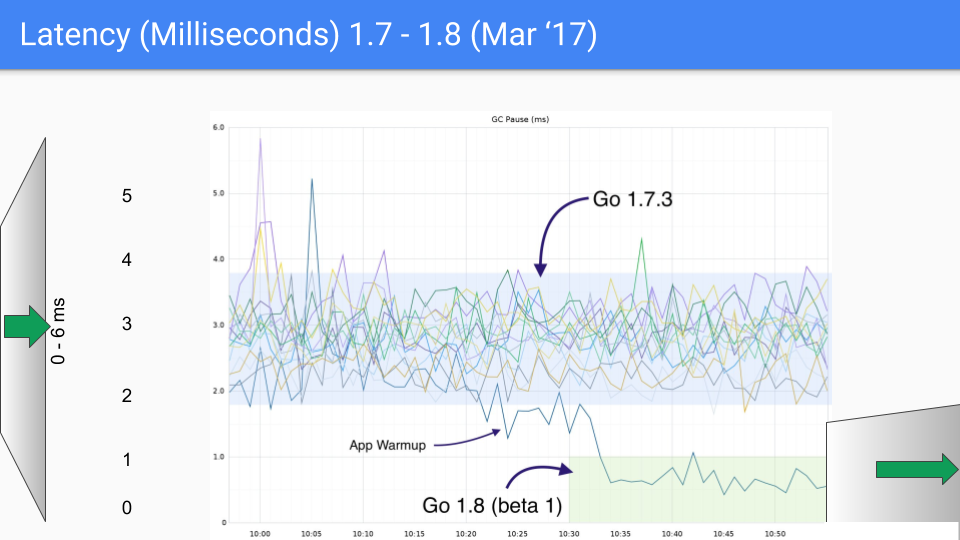
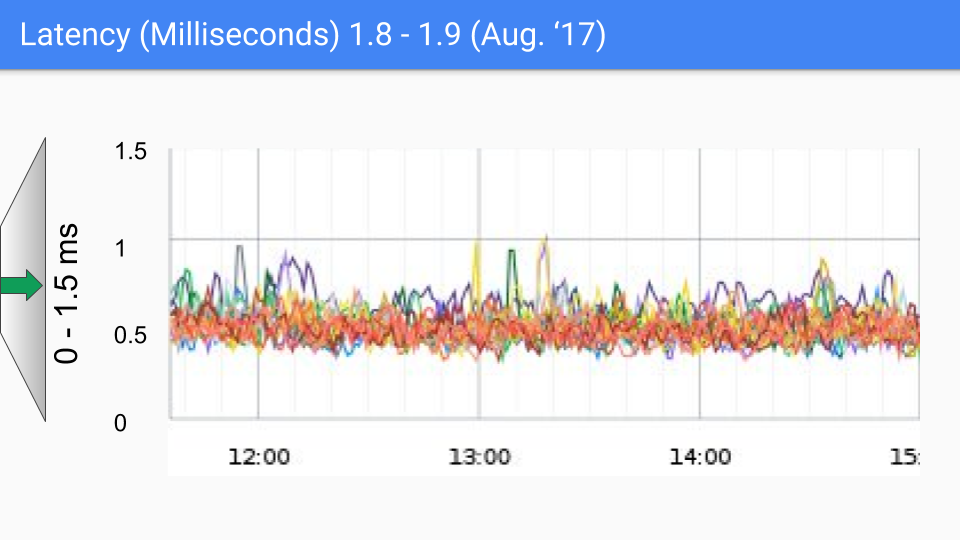
在写下本文时,go 的最新版本已经快要来到了 go1.23,对于如今的 go 来讲,GC 性能早已不算问题了,现在的 GC 延时大部分情况下都低于 100 微秒,满足绝大部分业务场景的需要。
总的来说,Go 中的垃圾回收可以分为下面几个阶段
- 扫描阶段:从栈和全局变量中收集根对象
- 标记阶段:将对象着色
- 标记终止阶段:处理善后工作,关闭屏障
- 回收阶段:释放和回收垃圾对象的内存
概念
在官方文档和文章中可能会出现以下的一些概念,下面简单的解释说明一下
- 赋值器(mutator):一种术语化的表达方式,指的是用户程序,在 go 中指的是用户代码
- 收集器(collector):指的就是负责垃圾回收的程序,在 go 中负责垃圾回收的就是运行时
- 终结器(finalizer):指的是在标记扫描工作完成后,负责回收释放清理对象内存的代码
- 控制器:指的是
runtime.gcController全局变量,它的类型为gcControllerState,后者实现了调步算法,负责确认何时进行垃圾回收和执行多少工作量。 - 限制器:指的是
runtime.gcCPULimiter,它负责在垃圾回收时防止 CPU 占用率过高而影响到用户程序
触发
func gcStart(trigger gcTrigger)垃圾回收由runtime.gcStart函数来开启,它只接收参数runtime.gcTrigger结构体,其中包含了 GC 触发的原因,当前时间,以及这是第几轮 GC。
type gcTrigger struct {
kind gcTriggerKind
now int64 // gcTriggerTime: current time
n uint32 // gcTriggerCycle: cycle number to start
}其中gcTriggerKind有以下几种可选值
const (
// gcTriggerHeap indicates that a cycle should be started when
// the heap size reaches the trigger heap size computed by the
// controller.
gcTriggerHeap gcTriggerKind = iota
// gcTriggerTime indicates that a cycle should be started when
// it's been more than forcegcperiod nanoseconds since the
// previous GC cycle.
gcTriggerTime
// gcTriggerCycle indicates that a cycle should be started if
// we have not yet started cycle number gcTrigger.n (relative
// to work.cycles).
gcTriggerCycle
)总的来说垃圾回收的触发时机有三种
创建新对象时:在调用
runtime.mallocgc分配内存时,如果监测到堆内存达到了阈值(一般来说是上一次 GC 时的两倍,该值也会被调步算法进行调整),便会开启垃圾回收func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { ... if shouldhelpgc { if t := (gcTrigger{kind: gcTriggerHeap}); t.test() { gcStart(t) } } ... }定时强制触发:go 在运行时会启动一个单独的协程来运行
runtime.forcegchelper函数,如果长时间没有进行垃圾回收,它便会强制开启 GC,这个时间由runtime.forcegcperiod常量决定,其值为 2 分钟,同时在系统监控协程中也会定时检查是否需要强制 GCfunc forcegchelper() { for { ... gcStart(gcTrigger{kind: gcTriggerTime, now: nanotime()}) ... } }func sysmon() { ... for { ... // check if we need to force a GC if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && forcegc.idle.Load() { lock(&forcegc.lock) forcegc.idle.Store(false) var list gList list.push(forcegc.g) injectglist(&list) unlock(&forcegc.lock) } } }手动触发:通过
runtime.GC函数,用户可以手动触发垃圾回收。func GC() { ... n := work.cycles.Load() gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1}) ... }
提示
感兴趣可以前往Go Gc Pacer Re-Design阅读英文原文,里面讲解了有关于触发 GC 的调步算法(pacing algorithm)的设计理念和改进,因其内容比较复杂涉及过多的数学公式,正文中不做过多阐述。
标记
现如今 Go 的 GC 算法依然是先标记后清除这样一个步骤,但其实现不再像以前一样简单。
标记-清除
先从最简单的标记清除算法开始讲起,在内存中,对象与对象之间的引用关系会构成一个图,垃圾回收的工作就在这个图上进行,工作分为两个阶段:
- 标记阶段:从根节点(根节点通常是栈上的变量,全局变量等活跃对象)开始,逐个遍历每一个可以到达的节点,并将其标记为活跃对象,直到遍历完所有可以到达的节点,
- 清除阶段:遍历堆中的所有对象,将未标记的对象回收,将其内存空间释放或是复用。
在回收的过程中,对象图的结构不能被改变,所以要将整个程序停止,也就是 STW,回收完毕以后才能继续运行,这种算法的缺点就在于耗时较长,比较影响程序的运行效率,这是早期版本 Go 使用的标记算法,它的缺点比较明显
- 会产生内存碎片(由于 Go TCMalloc 式的内存管理方式,碎片问题的影响并不大)
- 在标记阶段会扫描堆的所有对象
- 会导致 STW,暂停整个程序,且时间不短
三色标记
为了改进效率,Go 采用了经典的三色标记算法,所谓三色,指的是黑灰白三色:
- 黑色:在标记过程中对象已访问过,并且它所直接引用的对象也都已经访问过,表示活跃的对象
- 灰色:在标记过程中对象已访问过,但它所直接引用的对象并未全部访问,当全部访问完后会转变为黑色,表示活跃的对象
- 白色:在标记过程中从未被访问过,在访问过后会变为灰色,表示可能为垃圾对象,
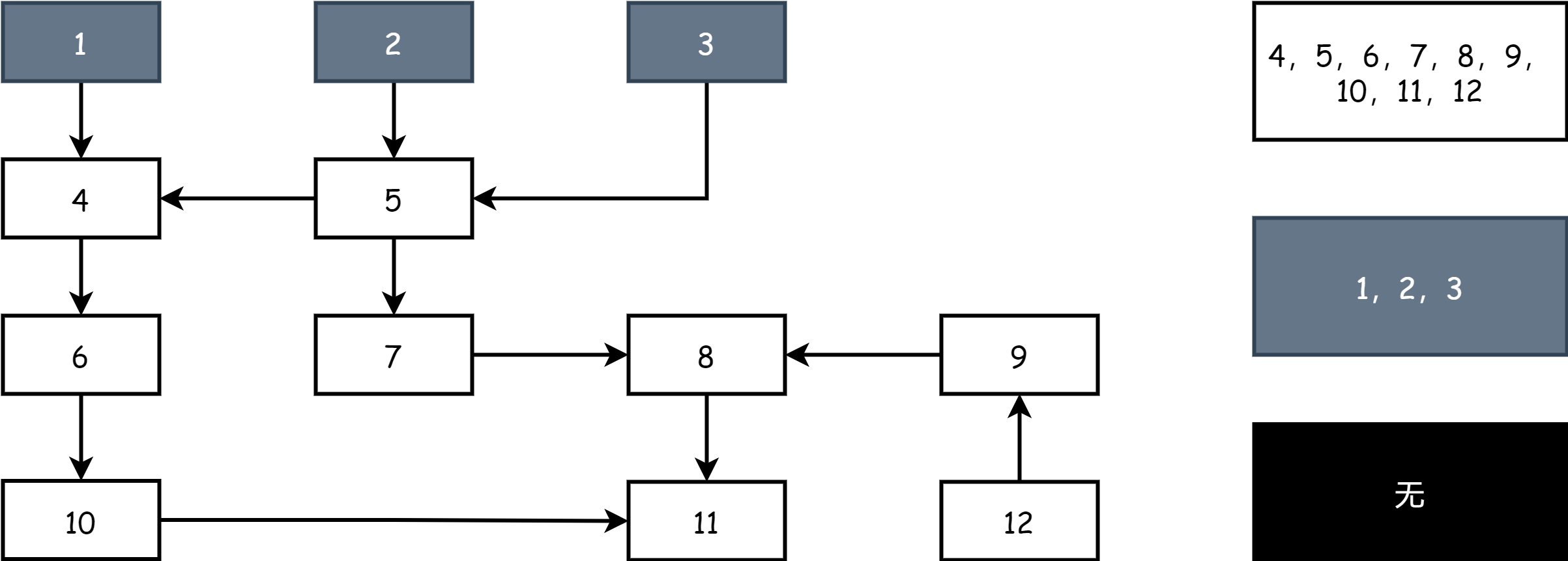
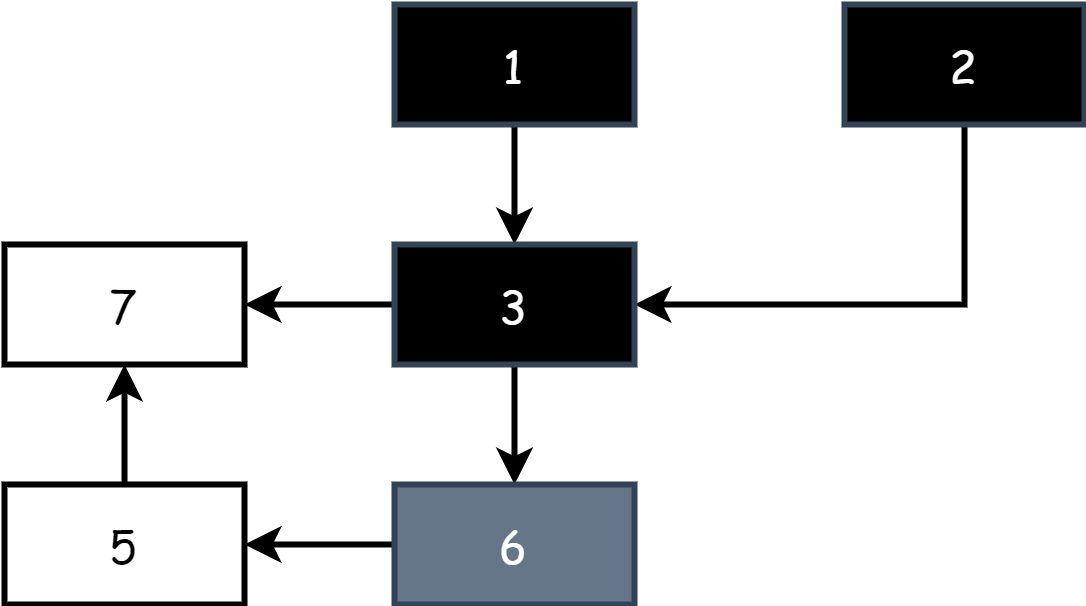
在三色标记工作开始时,场上只有灰色和白色对象,所有根对象都是灰色,其它对象都是白色,如下图所示
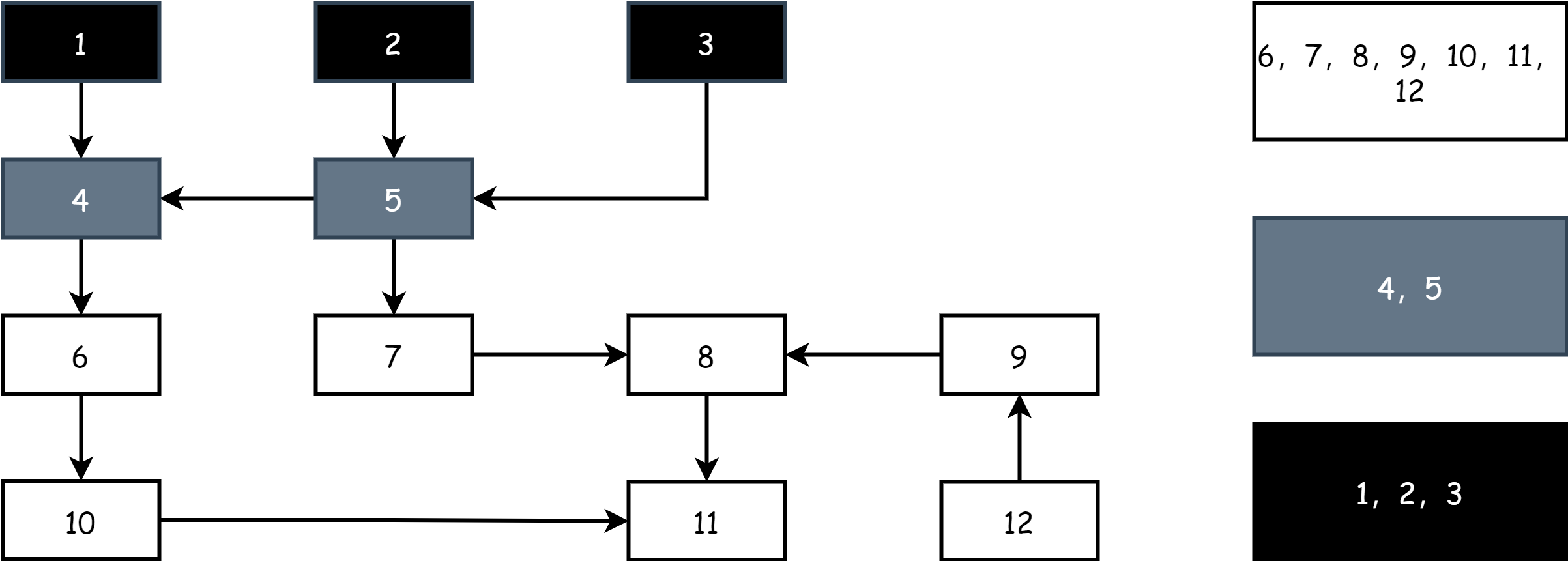
每一轮标记开始时,先从灰色对象开始,将灰色对象标记为黑色,表示其为活跃对象,然后再将黑色对象所有直接引用的对象标记为灰色,剩下的就是白色,此时场上就有了黑白灰三种颜色。
不断重复上述步骤,直到场上只剩下黑色和白色对象,当灰色对象集合为空时,就代表着标记结束,如下图
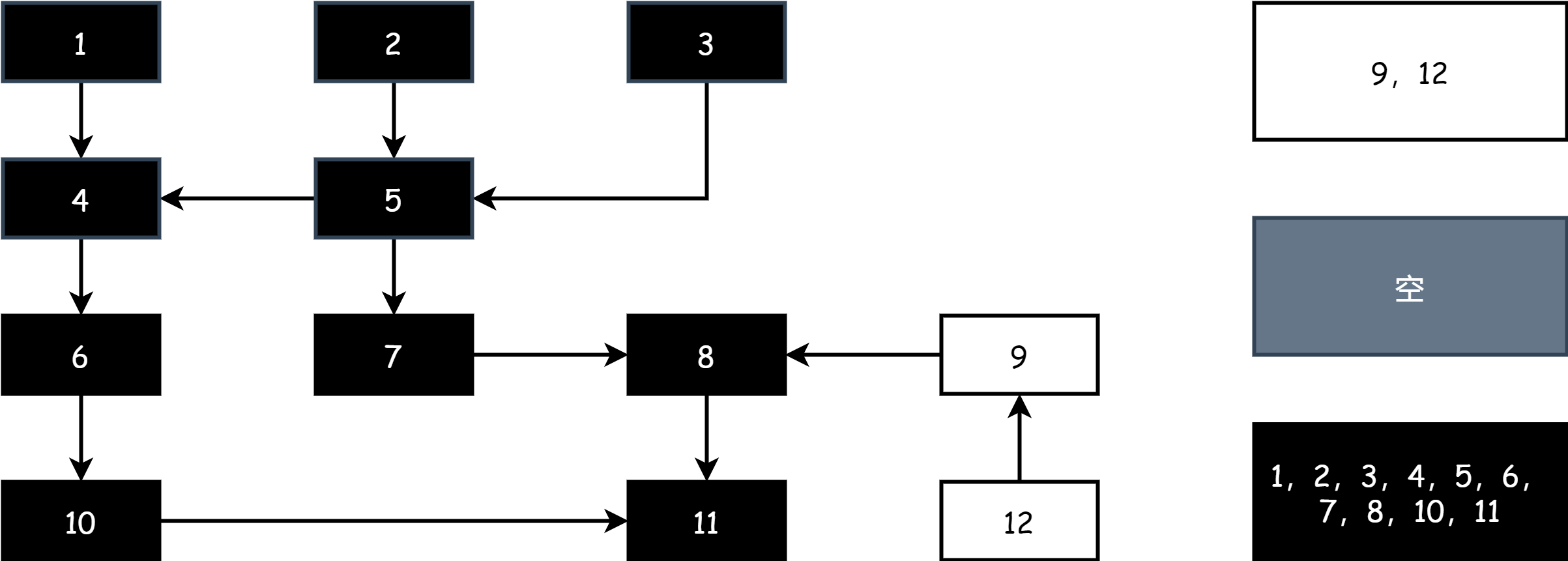
在标记结束后,在清除阶段只需将白色集合中对象的内存释放即可。
不变性
三色标记法本身没法进行并发标记(指程序一边运行一边标记),如果在标记时对象图结构发生了改变,这可能会导致两种情况
- 多标:在对象被标记为黑色对象后,用户程序删除了对于该对象的所有引用,那么它应该是白色对象需要被清除
- 漏标:在对象被标记为白色对象后,用户程序中有其它对象引用了该对象,那么它应该是黑色对象不应该被清除
对于第一种情况其实可以接受,因为未被清理的对象可以在下一轮回收中被处理掉。但第二种情况就没法接受了,正在使用中的对象内存被错误的释放,会造成严重的程序错误,这是必须要避免的问题。
三色不变性这一概念来自于 Pekka P. Pirinen 于 1998 年发表的论文《Barrier techniques for incremental tracing》,它指在并发标记时的对象颜色的两个不变性:
强三色不变性:黑色对象不可以直接引用白色对象
弱三色不变性:当黑色对象直接引用白色对象时,必须有另一个灰色对象可以直接或间接访问到该灰色对象,称作受到灰色对象的保护
对于强三色不变性而言,已知黑色对象 3 是已经访问过的对象,且其子对象也全都访问过并标记为灰色对象,如果此时用户程序并发的给黑色对象 3 添加白色对象 7 的新引用,正常来说白色对象 7 应该被标记为灰色,但由于黑色对象 3 已经被访问过了,对象 7 不会被访问,所以它始终都是白色对象,并最终被错误的清理掉。

对于弱三色不变性而言,它其实跟强三色不变性同理,因为灰色对象能够直接或间接的访问到该白色对象,后续标记过程中它最终会被标记为灰色对象,从而避免被误清理。
通过不变性,可以确保在标记过程中不会有对象被误清理,也就能保证并发条件下的标记工作的正确性,从而可以使得三色标记并发的工作,这样一来其标记效率相比于标记-清除算法会提升相当多。要在并发情况下保证三色不变性,关键就在于屏障技术。
标记工作
在 GC 扫描阶段时,有一个全局变量runtime.gcphase用于表示 GC 的状态,有如下可选值:
_GCoff:标记工作未开始_GCmark:标记工作已开始_GCmarktermination:标记工作将要终止
当标记工作开始时,runtime.gcphase的状态为_GCmark,执行标记工作的是runtime.gcDrain函数,其中runtime.gcWork参数是一个缓冲池,它存放着要追踪的对象指针。
func gcDrain(gcw *gcWork, flags gcDrainFlags)在工作时,它会尝试从缓冲池去获取可追踪的指针,如果有的话则会调用runtime.scanobject函数继续执行扫描任务,它的作用是不断的扫描缓冲区中的对象,将它们染黑。
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Flush the write barrier
// buffer; this may create
// more work.
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
// Unable to get work.
break
}
scanobject(b, gcw)当 P 被抢占或将发生 STW 时,扫描工作才会停止
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
...
scanobject(b, gcw)
...
}runtime.gcwork是一个采用了生产者/消费者模型的队列,该队列负责存放待扫描的灰色对象,每一个处理器 P 本地都有这样一个队列,对应``runtime.p.gcw`字段。
func scanobject(b uintptr, gcw *gcWork) {
...
for {
var addr uintptr
if hbits, addr = hbits.nextFast(); addr == 0 {
if hbits, addr = hbits.next(); addr == 0 {
break
}
}
scanSize = addr - b + goarch.PtrSize
obj := *(*uintptr)(unsafe.Pointer(addr))
if obj != 0 && obj-b >= n {
if obj, span, objIndex := findObject(obj, b, addr-b); obj != 0 {
greyobject(obj, b, addr-b, span, gcw, objIndex)
}
}
}
gcw.bytesMarked += uint64(n)
gcw.heapScanWork += int64(scanSize)
}runitme.scanobject函数在扫描时会不断的将可达的白色对象标记为灰色,然后通过调用gcw.put放入本地的队列中,同时gcDrain函数也会不断的通过gcw.tryget来尝试获取灰色对象以继续扫描。标记扫描的过程是增量式的,不需要一口气完成所有的标记工作,标记任务因一些原因被抢占时就会中断,等到恢复后可以根据队列中剩余的灰色对象继续完成标记工作。
后台标记
标记工作并不会在 GC 开始时立即执行,在刚触发 GC 时,go 会创建与当前处理器 P 总数量相同的标记任务,它们会被添加到全局任务队列中,然后进入休眠直到在标记阶段被唤醒。在运行时,由runtime.gcBgMarkStartWorkers来进行任务的分配,标记任务实际上指的就是runtime.gcBgMarkWorker函数,其中gcBgMarkWorkerCount和gomaxprocs两个运行时全局变量分别表示当前 worker 的数量和处理器 P 的数量。
func gcBgMarkStartWorkers() {
// Background marking is performed by per-P G's. Ensure that each P has
// a background GC G.
//
// Worker Gs don't exit if gomaxprocs is reduced. If it is raised
// again, we can reuse the old workers; no need to create new workers.
for gcBgMarkWorkerCount < gomaxprocs {
go gcBgMarkWorker()
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
// The worker is now guaranteed to be added to the pool before
// its P's next findRunnableGCWorker.
gcBgMarkWorkerCount++
}
}在 worker 启动后,它会创建一个runtime.gcBgMarkWorkerNode结构体,将其加入全局的 worker 池runitme.gcBgMarkWorkerPool,然后调用runtime.gopark函数让协程其陷入休眠
func gcBgMarkWorker() {
...
node := new(gcBgMarkWorkerNode)
node.gp.set(gp)
notewakeup(&work.bgMarkReady)
for {
// Go to sleep until woken by
// gcController.findRunnableGCWorker.
gopark(func(g *g, nodep unsafe.Pointer) bool {
node := (*gcBgMarkWorkerNode)(nodep)
// Release this G to the pool.
gcBgMarkWorkerPool.push(&node.node)
// Note that at this point, the G may immediately be
// rescheduled and may be running.
return true
}, unsafe.Pointer(node), waitReasonGCWorkerIdle, traceBlockSystemGoroutine, 0)
}
...
}有两种情况可以唤醒 worker
- 处于标记阶段时,调度循环会通过
runtime.runtime.gcController.findRunnableGCWorker函数来唤醒休眠的 worker - 处于标记阶段时,如果处理器 P 当前为空闲状态,调度循环会尝试直接从全局 worker 池
gcBgMarkWorkerPool中获取可用的 worker
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
top:
// Try to schedule a GC worker.
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
...
// We have nothing to do.
//
// If we're in the GC mark phase, can safely scan and blacken objects,
// and have work to do, run idle-time marking rather than give up the P.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() {
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop())
if node != nil {
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := node.gp.ptr()
trace := traceAcquire()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.ok() {
trace.GoUnpark(gp, 0)
traceRelease(trace)
}
return gp, false, false
}
gcController.removeIdleMarkWorker()
}
...
}处理器 P 有结构体中有一个字段gcMarkWorkerMode来表示标记任务的执行模式,它有以下几个可选值:
gcMarkWorkerNotWorker:表示当前处理器 P 没有正在执行标记任务gcMarkWorkerDedicatedMode:表示当前处理器 P 专门用于执行标记任务,且期间不会被抢占。gcMarkWorkerFractionalMode:表示当前处理器是因为 GC 利用率不达标(25%达标)才执行的标记任务,执行期间可以被抢占。假设当前处理器 P 数量为 5,根据计算公式此时需要一个专用处理标记任务的处理器 P,利用率只达到了 20%,剩下 5%的利用率就需要开启一个FractionalMode的处理器 P 来弥补。具体的计算代码如下所示func (c *gcControllerState) startCycle(markStartTime int64, procs int, trigger gcTrigger) { ... totalUtilizationGoal := float64(procs) * gcBackgroundUtilization dedicatedMarkWorkersNeeded := int64(totalUtilizationGoal + 0.5) if float64(dedicatedMarkWorkersNeeded) > totalUtilizationGoal { // Too many dedicated workers. dedicatedMarkWorkersNeeded-- } c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(dedicatedMarkWorkersNeeded)) / float64(procs) ... }gcMarkWorkerIdleMode:表示当前处理器是因为空闲才执行标记任务,执行期间可以被抢占。
Go 团队不希望 GC 占用过多的性能从而影响用户程序的正常运行,根据这些不同的模式进行标记工作,可以在不浪费性能也不影响用户程序的情况下完成 GC。可以注意到的是标记任务的基本分配单位是处理器 P,所以标记工作是并发进行的,多个标记任务和用户程序之间并发的执行,互不影响。
标记辅助
协程 G 在运行时有一个字段gcAssistBytes,这里将其称为 GC 辅助积分。处于 GC 标记状态时,当一个协程尝试申请若干大小的内存,它会被扣除与申请内存大小相同的积分。如果此时积分为负数,那么该协程必须辅助完成定量的 GC 扫描任务来偿还积分,当积分为正数时,协程就可以不需要去完成辅助标记任务了。
扣除积分的函数为runtime.deductAssistCredit,它会在runtime.mallocgc函数分配内存前被调用。
func deductAssistCredit(size uintptr) *g {
var assistG *g
if gcBlackenEnabled != 0 {
// Charge the current user G for this allocation.
assistG = getg()
if assistG.m.curg != nil {
assistG = assistG.m.curg
}
// Charge the allocation against the G. We'll account
// for internal fragmentation at the end of mallocgc.
assistG.gcAssistBytes -= int64(size)
if assistG.gcAssistBytes < 0 {
// This G is in debt. Assist the GC to correct
// this before allocating. This must happen
// before disabling preemption.
gcAssistAlloc(assistG)
}
}
return assistG
}然而当协程完成定量的辅助扫描工作后,就会偿还定量的积分给当前协程,实际负责辅助标记的函数是runtime.gcDrainN。
func gcAssistAlloc1(gp *g, scanWork int64) {
...
gcw := &getg().m.p.ptr().gcw
// 完成工作了
workDone := gcDrainN(gcw, scanWork)
...
assistBytesPerWork := gcController.assistBytesPerWork.Load()
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(workDone))
...
}由于扫描是并发的,记录下来的工作量中只有一部分是当前协程的,余下的工作量会根据辅助队列的顺序来逐个偿还给其它协程,如果还有剩余的话,就会添加到全局积分gcController.assistBytesPerWork中。
func gcFlushBgCredit(scanWork int64) {
// 如果队列为空则直接添加到全局积分中
if work.assistQueue.q.empty() {
gcController.bgScanCredit.Add(scanWork)
return
}
assistBytesPerWork := gcController.assistBytesPerWork.Load()
scanBytes := int64(float64(scanWork) * assistBytesPerWork)
lock(&work.assistQueue.lock)
for !work.assistQueue.q.empty() && scanBytes > 0 {
gp := work.assistQueue.q.pop()
if scanBytes+gp.gcAssistBytes >= 0 {
scanBytes += gp.gcAssistBytes
gp.gcAssistBytes = 0
ready(gp, 0, false)
} else {
gp.gcAssistBytes += scanBytes
scanBytes = 0
work.assistQueue.q.pushBack(gp)
break
}
}
// 还有剩余
if scanBytes > 0 {
assistWorkPerByte := gcController.assistWorkPerByte.Load()
scanWork = int64(float64(scanBytes) * assistWorkPerByte)
gcController.bgScanCredit.Add(scanWork)
}
unlock(&work.assistQueue.lock)
}相应的,当需要偿还的积分过多时(申请的内存过大),也可以使用全局积分来抵消部分自己的借债
func gcAssistAlloc(gp *g) {
...
assistWorkPerByte := gcController.assistWorkPerByte.Load()
assistBytesPerWork := gcController.assistBytesPerWork.Load()
debtBytes := -gp.gcAssistBytes
scanWork := int64(assistWorkPerByte * float64(debtBytes))
if scanWork < gcOverAssistWork {
scanWork = gcOverAssistWork
debtBytes = int64(assistBytesPerWork * float64(scanWork))
}
// 用全局积分抵押
bgScanCredit := gcController.bgScanCredit.Load()
stolen := int64(0)
if bgScanCredit > 0 {
if bgScanCredit < scanWork {
stolen = bgScanCredit
gp.gcAssistBytes += 1 + int64(assistBytesPerWork*float64(stolen))
} else {
stolen = scanWork
gp.gcAssistBytes += debtBytes
}
gcController.bgScanCredit.Add(-stolen)
scanWork -= stolen
if scanWork == 0 {
return
}
}
...
}标记辅助是在高负载的情况下的一种平衡手段,用户程序分配内存的速度远高于标记的速度,分配多少内存就进行多少标记工作。
标记终止
当所有可达的灰色对象都被染黑了过后,此时就由_GCmark状态过渡到_GCmarktermination状态,这个过程由runtime.gcMarkDone函数来完成。在开始时,它会检查是否仍有任务要执行,
top:
if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) {
return
}
gcMarkDoneFlushed = 0
// 将所有因写屏障拦截的标记操作全部批量的执行
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
if pp.gcw.flushedWork {
atomic.Xadd(&gcMarkDoneFlushed, 1)
pp.gcw.flushedWork = false
}
})
if gcMarkDoneFlushed != 0 {
goto top
}当没有任何全局任务和本地任务要执行后,调用runtime.stopTheWorldWithSema进行 STW,然后做一些收尾的工作
// Disable assists and background workers. We must do
// this before waking blocked assists.
atomic.Store(&gcBlackenEnabled, 0)
// Notify the CPU limiter that GC assists will now cease.
gcCPULimiter.startGCTransition(false, now)
// Wake all blocked assists. These will run when we
// start the world again.
gcWakeAllAssists()
// In STW mode, re-enable user goroutines. These will be
// queued to run after we start the world.
schedEnableUser(true)
// endCycle depends on all gcWork cache stats being flushed.
// The termination algorithm above ensured that up to
// allocations since the ragged barrier.
gcController.endCycle(now, int(gomaxprocs), work.userForced)
// Perform mark termination. This will restart the world.
gcMarkTermination(stw)首先将runtime.BlackenEnabled置为 0,表示标记工作已经结束了,通知限制器标记辅助已经结束了,关闭内存屏障,唤醒所有因辅助标记而休眠的协程,然后再重新唤醒所有的用户协程,还要收集本轮扫描工作的各种数据来调整调步算法来为下一轮扫描做准备,收尾工作完成后,调用runtime.gcSweep函数清理垃圾对象,最后再调用runtime.startTheWorldWithSema让程序恢复运行。
屏障
内存屏障的作用可以理解为 hook 了对象的赋值行为,在赋值前做一些指定的操作,这种 hook 代码通常在编译期间由编译器插入到代码中。前面提到过,三色标记在并发情况下添加和删除对象引用都会导致问题,由于这两个都是写操作(删除就是赋空值),所以拦截它们的屏障被统称为写屏障。但屏障机制并非毫无成本,拦截内存写操作会造成额外的开销,因此屏障机制只在堆上生效,考虑到实现复杂度和性能损耗,对于栈和寄存器则不起作用范围内。
提示
想要了解更多 Go 对于屏障技术的应用细节,前往Eliminate STW stack rescan阅读英文原文,本文参考了许多内容。
插入写屏障
插入写屏障由 Dijkstra 提出的,它满足强三色不变式。当给黑色对象添加了一个新的白色对象引用时,插入写屏障会拦截此操作,将该白色对象标记为灰色,这样可以避免黑色对象直接引用白色对象,保证了强三色不变性,这个相当好理解。

前面提到过写屏障不会应用在栈上,如果在并发标记的过程中栈对象的引用关系发生了变化,比如栈中的黑色对象引用了堆中的白色对象,所以为了确保栈对象的正确性,只能在标记结束后再次将栈中的所有对象全部标记为灰色对象,然后重新扫描一遍,等于是一轮标记要扫描两次栈空间,并且第二次扫描时必须要 STW,假如程序中同时存在成百上千个协程栈,那么这一扫描过程的耗时将不容忽视,根据官方统计的数据,重新扫描的耗时大概在 10-100 毫秒左右。
优点:扫描时不需要 STW
缺点:需要二次扫描栈空间保证正确性,需要 STW
删除写屏障
删除写屏障由 Yuasa 提出,又称基于起始快照的屏障,该方式在开始时需要 STW 来对根对象进行快照记录,并且它会将所有根对象标黑,所有的一级子对象标灰,这样其余的白色子对象都会处于灰色对象的保护之下。Go 团队并没有直接应用删除写屏障,而是选择了将其与插入写屏障混合使用,所以为了方便后续的理解,这里还是要讲一下。删除写屏障在并发条件下保证正确性的规则是:当从灰色或白色对象删除对白色对象的引用时,都会直接将白色对象标记为灰色对象。
分两种情况来解读:
删除灰色对象对于白色对象的引用:由于不知道白色对象下游是否被黑色对象引用,此举可能会切断灰色对象对于白色对象的保护
删除白色对象对于白色对象的引用:由于不知道白色对象上游是否被灰色保护,下游是否被黑色对象引用,此举也可能会切断灰色对于白色对象的保护
不管是哪种情况,删除写屏障都会将被引用的白色对象标记为灰色,这样一来就能满足弱三色不变式。这是一种保守的做法,因为上下游情况未知,将其标记为灰色就等于不再视其为垃圾对象,就算删除引用后会导致该对象不可达也就是成为垃圾对象时,也仍然会将其标记为灰色,它会在下轮扫描中被释放掉,这总好过对象被误清理而导致的内存错误。

优点:由于栈对象全黑,所以不需要二次扫描栈空间
缺点:在扫描开始时需要 STW 来对栈空间的根对象进行快照
混合写屏障
go1.8 版本引用了新的屏障机制:混合写屏障,即插入写屏障与删除写屏障的混合,结合了它们两个的优点:
- 插入写屏障起始时不需要 STW 来进行快照
- 删除写屏障不需要 STW 来二次扫描栈空间
下面是官方给出的的伪代码:
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptr简单讲解下里面的一些概念,其中slot是一个指针,表示对其它对象的引用,*slot是原对象,ptr是新对象,*slot=ptr是一次赋值操作,等于修改对象的引用,赋空值就是删除引用,shade()表示将一个对象标记为灰色,shade(*slot)就是将原对象标记为灰色,shade(ptr)就是将新对象标记为灰色,下面是一个例图,假设对象 1 原来引用着对象 2,然后用户程序修改了引用,让对象 1 引用了对象 3,混合写屏障捕捉到了这一行为,其中*slot代表的就是对象 2,ptr代表的就是对象 1。
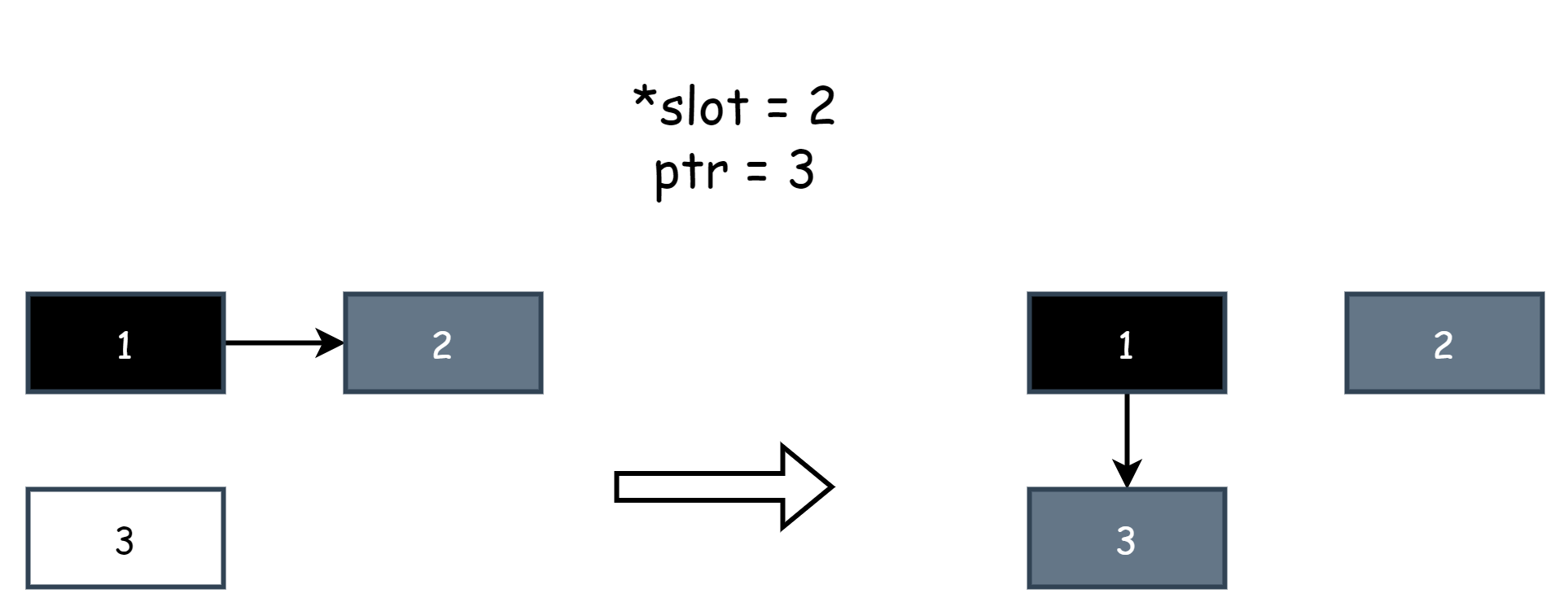
官方用一句话概括了上面伪代码的作用
the write barrier shades the object whose reference is being overwritten, and, if the current goroutine's stack has not yet been scanned, also shades the reference being installed.
翻译过来就是,当混合写屏障拦截到写操作时,会将原对象标记为灰色,如果当前协程栈还未被扫描过时,就将新对象也标记为灰色。
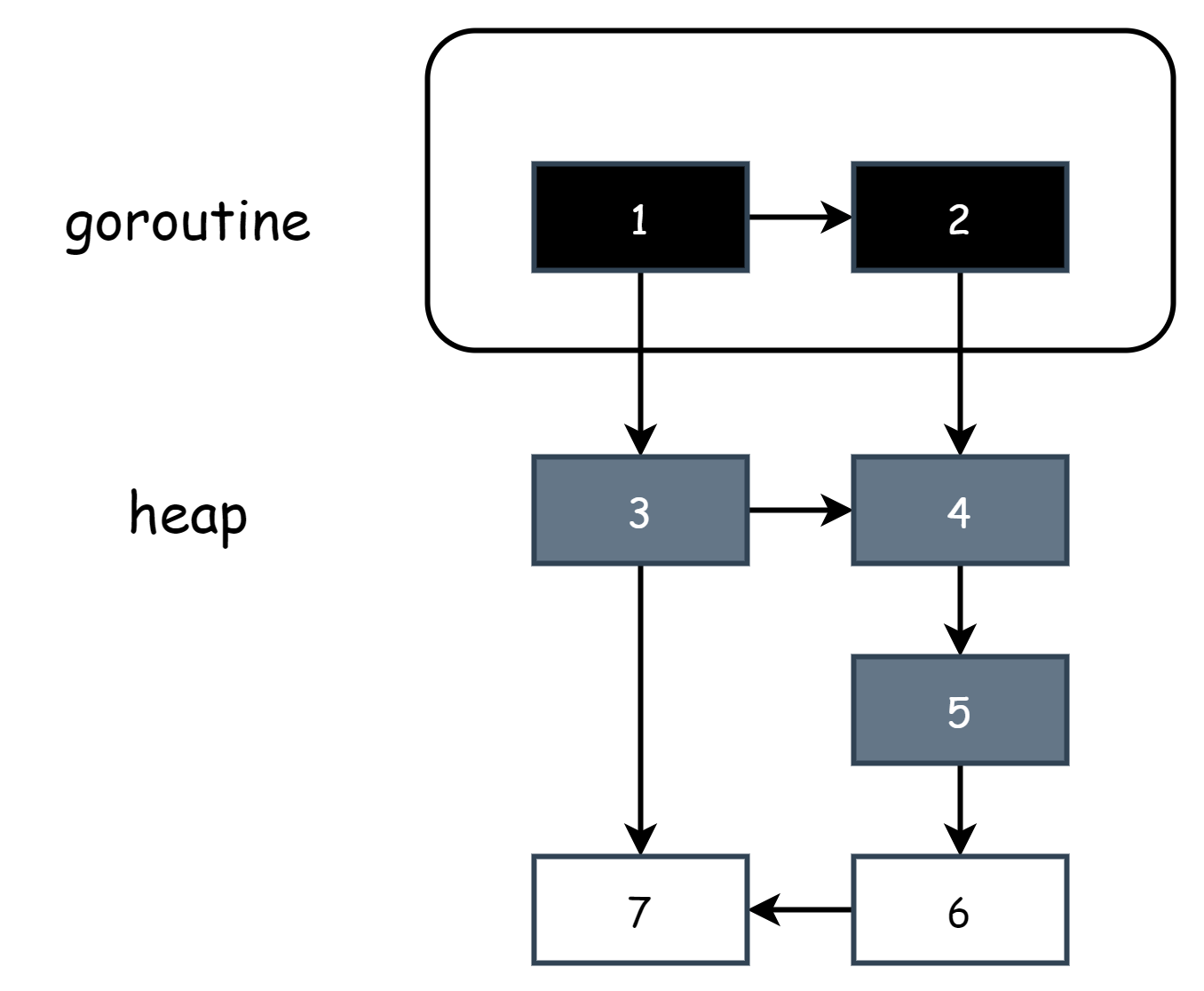
标记工作开始时,需要扫描栈空间以收集根对象,这时会直接将其全部标记为黑色,在此期间任何新创建对象也会被标记为黑色,保证栈中的所有都是黑色对象,所以伪代码中的current stack is grey表示的就是当前协程栈还未被扫描过,所以协程栈只有两种状态,要么全黑要么全灰,在由全灰变为全黑的过程中是需要暂停当前协程的,所以在混合写屏障下依然会有局部的 STW。当协程栈全黑时,此时一定满足强三色不变式,因为扫描后栈中的黑色对象只会引用灰色对象,不会存在黑色对象直接引用白色对象的情况,所以此时不需要插入写屏障,对应伪代码
if current stack is grey:
shade(ptr)但仍然需要删除写屏障来满足弱三色不变式,也就是
shade(*slot)在扫描完毕后,由于栈空间的对象已经是全黑的了,就不再需要去二次扫描栈空间了,可以节省掉 STW 的时间。
至此,也就是 go1.8 版本往后,Go 大体上确立了垃圾回收的基本框架,后续版本有关垃圾回收的优化也都是建立在混合写屏障的基础之上的,由于已经消除了大部分的 STW,此时垃圾回收的平均延时已经降低到了微秒级别。
着色缓存
在之前提到的屏障机制中,在拦截到写操作时都是立即标记对象颜色,在采用混合写屏障后,由于需要对原对象和新对象都行进行标记,所以工作量会翻倍,同时编译器插入的代码也会增加。为了进行优化,在 go1.10 版本中,写屏障在进行着色时不再会立即标记对象颜色,而是会将原对象和新对象存入一个缓存池中,等积攒到了一定数量后,再进行批量标记,这样做效率更高。
负责缓存的结构是runtime.wbBuf,它实际上是一个数组,大小为 512。
type wbBuf struct {
next uintptr
end uintptr
buf [wbBufEntries]uintptr
}每一个 P 本地都有这样一个缓存
type p struct {
...
wbBuf wbBuf
...
}在标记工作进行时,如果gcw队列中没有可用的灰色对象,就会将缓存中的对象放入本地队列中。
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
for !(gp.preempt && (preemptible || sched.gcwaiting.Load() || pp.runSafePointFn != 0)) {
if work.full == 0 {
gcw.balance()
}
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// 刷新写屏障缓存
wbBufFlush()
b = gcw.tryGet()
}
}
if b == 0 {
break
}
scanobject(b, gcw)
}
}另外一种情况是,当标记终止时,也会检查每一个 P 本地的wbBuf是否有剩下的灰色对象
func gcMarkDone() {
...
forEachP(waitReasonGCMarkTermination, func(pp *p) {
wbBufFlush1(pp)
pp.gcw.dispose()
})
...
}回收
在垃圾回收中,最重要的部分在于如何找出垃圾对象,也就是扫描标记工作,而在标记工作完成后,回收工作就相对没那么复杂,它只需要将未标记的对象回收释放就行。这部分代码主要在runtime/mgcsweep.go文件中,根据文件中注释可以得知 Go 中的回收算法分为两种。
对象回收
对象回收的工作会在标记终止阶段,由runtime.sweepone来完成清理工作,过程是异步的。在清理时,它会尝试在内存单元中寻找未标记的对象,然后回收掉。倘若整个内存单元都未被标记,那么这一个单元都会被回收掉。
func sweepone() uintptr {
sl := sweep.active.begin()
npages := ^uintptr(0)
var noMoreWork bool
for {
s := mheap_.nextSpanForSweep()
if s == nil {
noMoreWork = sweep.active.markDrained()
break
}
if state := s.state.get(); state != mSpanInUse {
continue
}
// 尝试获取回收器
if s, ok := sl.tryAcquire(s); ok {
npages = s.npages
// 清理
if s.sweep(false) {
mheap_.reclaimCredit.Add(npages)
} else {
npages = 0
}
break
}
}
sweep.active.end(sl)
return npages
}对于对象回收算法而言,回收整个单元比较的困难,所以就有了第二个回收算法。
单元回收
单元回收的工作是在内存分配前进行的,由runtime.mheap.reclaim方法来完成,它会在堆中寻找所有对象都未被标记的内存单元,然后将整个单元回收。
func (h *mheap) reclaim(npage uintptr) {
mp := acquirem()
trace := traceAcquire()
if trace.ok() {
trace.GCSweepStart()
traceRelease(trace)
}
arenas := h.sweepArenas
locked := false
for npage > 0 {
if credit := h.reclaimCredit.Load(); credit > 0 {
take := credit
if take > npage {
take = npage
}
if h.reclaimCredit.CompareAndSwap(credit, credit-take) {
npage -= take
}
continue
}
idx := uintptr(h.reclaimIndex.Add(pagesPerReclaimerChunk) - pagesPerReclaimerChunk)
if idx/pagesPerArena >= uintptr(len(arenas)) {
h.reclaimIndex.Store(1 << 63)
break
}
nfound := h.reclaimChunk(arenas, idx, pagesPerReclaimerChunk)
if nfound <= npage {
npage -= nfound
} else {
h.reclaimCredit.Add(nfound - npage)
npage = 0
}
}
trace = traceAcquire()
if trace.ok() {
trace.GCSweepDone()
traceRelease(trace)
}
releasem(mp)
}对于内存单元而言,有一个sweepgen字段用于表明其回收状态
mspan.sweepgen == mheap.sweepgen - 2:该内存单元需要回收mspan.sweepgen == mheap.sweepgen - 1:该内存单元正在被回收mspan.sweepgen == mheap.sweepgen:该内存单元已经被回收了,可以正常使用mspan.sweepgen == mheap.sweepgen + 1:内存单元在缓存中,且需要回收mspan.sweepgen == mheap.sweepgen + 3:内存单元已经被回收了,但仍然在缓存中
mheap.sweepgen会随着 GC 轮次而增加,并且每一次都会+2。