select
select
select 是一种可以同时监听多个管道状态的结构,它的语法跟 switch 类似
import (
"context"
"log/slog"
"os"
"os/signal"
"time"
)
func main() {
finished := make(chan struct{})
ctx, stop := signal.NotifyContext(context.Background(), os.Kill, os.Interrupt)
defer stop()
slog.Info("running")
go func() {
time.Sleep(time.Second * 2)
finished <- struct{}{}
}()
select {
case <-ctx.Done():
slog.Info("shutting down")
case <-finished:
slog.Info("finished")
}
}这段代码通过将 context,管道,select 三者结合使用实现了一个简单的程序平滑退出的逻辑,代码中 select 同时监听着ctx.Done和finished两个管道,它退出的条件有两个,一是操作系统发送退出信号,二是finished管道有消息可以读取即用户代码任务完成,这样我们就可以在程序退出时做收尾工作。
众所周知,select 有两个非常重要的特性,一是非阻塞,在管道的发送与接收的源代码中可以看到对于 select 做了一些处理,可以在非阻塞的情况下判断管道是否可用,二是随机化,如果有多个管道可用的话它会随机选一个来执行,不遵守既定的顺序可以让每个管道都相对公平地得到执行,否则在极端情况下一些管道可能永远也不会被处理。因为它的工作全部都跟管道有关,所以先建议阅读chan这篇文章,了解了管道后再来了解 select 会畅通很多。
结构
运行时只有一个runtime.scase结构体表示 select 的分支,每一个case的运行时表示就是scase。
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}其中的c指的是管道,elem表示接收或发送元素的指针,实际上 select 关键字指的是runtime.selectgo函数。
原理
select 的使用方式被 go 分成了四种情况来进行优化,这一点可以在cmd/compile/internal/walk.walkSelectCases函数中看到对于这四种情况的处理逻辑。
func walkSelectCases(cases []*ir.CommClause) []ir.Node {
ncas := len(cases)
sellineno := base.Pos
// optimization: zero-case select
if ncas == 0 {
return []ir.Node{mkcallstmt("block")}
}
// optimization: one-case select: single op.
if ncas == 1 {
...
}
// optimization: two-case select but one is default: single non-blocking op.
if ncas == 2 && dflt != nil {
...
}
...
return init
}优化
编译器会对前三种情况进行优化,第一种情况是 case 数量为 0 时即一个空的 select,我们都知道空的 select 语句会造成当前协程永久阻塞。
select{}之所以会阻塞是因为编译器将其翻译成了对runtime.block函数的直接调用
func block() {
gopark(nil, nil, waitReasonSelectNoCases, traceBlockForever, 1) // forever
}而block函数又调用了runtime.gopark函数,使得当前协程变为_Gwaitting状态,并进入永久阻塞,再也不会得到调度。
第二种情况,只有一个 case 且不是 default,这种情况编译器会直接将其翻译成对管道的收发操作,并且还是阻塞式的,例如下面的这种代码
func main() {
ch := make(chan int)
select {
case <-ch:
// do something
}
}它会被翻译成对runtime.chanrecv1函数的直接调用,从汇编代码中就可以看出来
TEXT main.main(SB), ABIInternal, $2
...
LEAQ type:chan int(SB), AX
XORL BX, BX
PCDATA $1, $0
CALL runtime.makechan(SB)
XORL BX, BX
NOP
CALL runtime.chanrecv1(SB)
ADDQ $16, SP
POPQ BP
...在只有一个 case 的情况下对管道进行发送数据也是同样的道理,它会被翻译成对runtime.chansend1函数的直接调用,同样也是阻塞式的。
第三种情况,有两个 case 且其中一个是 default
func main() {
ch := make(chan int)
select {
case ch <- 1:
// do something
default:
// do something
}
}这种情况会将其翻译成一个对runtime.selectnbsend调用的if语句,如下
if selectnbsend(ch, 1) {
// do something
} else {
// do something
}如果是接收管道数据就会翻译成对runtime.selectnbrecv的调用
ch := make(chan int)
select {
case x, ok := <-ch:
// do something
default:
// do something
}if selected, ok = selectnbrecv(&v, c); selected {
// do something
} else {
// do something
}指的是注意的是,这种情况下对管道的接收或发送是非阻塞式的,我们可以很明显的看到其中的blcok参数为false。
func selectnbsend(c *hchan, elem unsafe.Pointer) (selected bool) {
return chansend(c, elem, false, getcallerpc())
}
func selectnbrecv(elem unsafe.Pointer, c *hchan) (selected, received bool) {
return chanrecv(c, elem, false)
}而不论是对管道发送或接收数据,在blcok为false时都有一个快速路径可以在不加锁的情况下判断是否可以发送或接收数据,正如下所示
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
if !block && empty(c) {
if atomic.Load(&c.closed) == 0 {
return
}
return true, false
}
...
}
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
if !block && c.closed == 0 && full(c) {
return false
}
...
}对于读取管道时,如果管道是空的就会直接返回,对于写管道时,如果管道未关闭且已经满了也会直接返回,在一般情况下它们是会造成协程阻塞的,但是与 select 结合使用就不会。
处理
上面三种只是对特殊情况的优化,正常使用的 select 关键字会被翻译成对runtime.selectgo函数的调用,它的处理逻辑长达 400 多行。
func selectgo(cas0 *scase, order0 *uint16, pc0 *uintptr, nsends, nrecvs int, block bool) (int, bool)编译器会将所有的 case 语句收集一个scase数组,然后传递给selectgo函数,处理完成后返回两个返回值
- 第一个是随机选取的管道下标,表示哪一个管道被处理了,没有的话返回-1
- 第二个表示对于读管道操作而言是否成功读取
这里简单解释下其参数
cas0,scase数组的头部指针,前半部分存放的是写管道 case,后半部分存放的读管道 case,以nsends来区分order0,它的长度是scase数组的两倍,前半部分分配给pollorder数组,后半部分分配给lockorder数组nsends和nrecvs表示读/写管道 case 的数量,两者之和就是 case 的总数block表示是否阻塞,如果有defaultcase 就代表非阻塞,其值为true,否则为true。pc0,指向一个[ncases]uintptr的数组头部,用于竞态分析,后面可以忽略它,对于理解 select 而言没什么帮助
假设有下面的代码
func main() {
ch := make(chan int)
select {
case ch <- 1:
println(1)
case ch <- 2:
println(2)
case ch <- 3:
println(3)
case ch <- 4:
println(4)
default:
println("default")
}
}查看其汇编形式,这里为了方便理解省去了部分代码
0x0000 00000 TEXT main.main(SB), ABIInterna
...
0x0023 00035 CALL runtime.makechan(SB)
0x0028 00040 MOVQ $1, main..autotmp_2+72(SP) // 1 2 3 4几个临时变量
0x0031 00049 MOVQ $2, main..autotmp_4+64(SP)
0x003a 00058 MOVQ $3, main..autotmp_6+56(SP)
0x0043 00067 MOVQ $4, main..autotmp_8+48(SP)
...
0x00c8 00200 CALL runtime.selectgo(SB) // 调用runtime.selectgo函数
0x00cd 00205 TESTQ AX, AX
0x00d0 00208 JLT 352 // 跳转到default分支
0x00d6 00214 PCDATA $1, $-1
0x00d6 00214 JEQ 320 // 跳转到分支4
0x00d8 00216 CMPQ AX, $1
0x00dc 00220 JEQ 288 // 跳转到分支3
0x00de 00222 NOP
0x00e0 00224 CMPQ AX, $2
0x00e4 00228 JNE 258 // 跳转到分支2
0x00e6 00230 PCDATA $1, $0
0x00e6 00230 CALL runtime.printlock(SB)
0x00eb 00235 MOVL $3, AX
0x00f0 00240 CALL runtime.printint(SB)
0x00f5 00245 CALL runtime.printnl(SB)
0x00fa 00250 CALL runtime.printunlock(SB)
0x00ff 00255 NOP
0x0100 00256 JMP 379
0x0102 00258 CALL runtime.printlock(SB)
0x0107 00263 MOVL $4, AX
0x010c 00268 CALL runtime.printint(SB)
0x0111 00273 CALL runtime.printnl(SB)
0x0116 00278 CALL runtime.printunlock(SB)
0x011b 00283 JMP 379
0x011d 00285 NOP
0x0120 00288 CALL runtime.printlock(SB)
0x0125 00293 MOVL $2, AX
0x012a 00298 CALL runtime.printint(SB)
0x012f 00303 CALL runtime.printnl(SB)
0x0134 00308 CALL runtime.printunlock(SB)
0x0139 00313 JMP 379
0x013b 00315 NOP
0x0140 00320 CALL runtime.printlock(SB)
0x0145 00325 MOVL $1, AX
0x014a 00330 CALL runtime.printint(SB)
0x014f 00335 CALL runtime.printnl(SB)
0x0154 00340 CALL runtime.printunlock(SB)
0x0159 00345 JMP 379
0x015b 00347 NOP
0x0160 00352 CALL runtime.printlock(SB)
0x0165 00357 LEAQ go:string."default\n"(SB)
0x016c 00364 MOVL $8, BX
0x0171 00369 CALL runtime.printstring(SB)
0x0176 00374 CALL runtime.printunlock(SB)
0x017b 00379 PCDATA $1, $-1
0x017b 00379 ADDQ $160, SP
0x0182 00386 POPQ BP
0x0183 00387 RET可以看到在调用selectgo函数后是有一个判断+跳转逻辑存在的,通过这些我们不难反推出其原来的样子
casei, ok := runtime.selectgo()
if casei == -1 {
println("default")
} else if casei == 3 {
println(4)
} else if casei == 2 {
println(3)
} else if casei == 1 {
println(2)
} else {
println(1)
}编译器生成的实际代码可能和这个有出入,但大致意思是差不多的。所以编译器会在调用完selectgo函数后同时使用if语句来判断轮到哪一个管道被执行,并且在调用之前,编译器还会生成一个 for 循环来收集scase数组不过这里省略掉了。
在知晓了外部是如何使用selectgo函数以后,下面就来了解selectgo函数内部是如何工作的。它首先会初始化几个数组,nsends+nrecvs表示 case 的总数,从下面的代码也可以看出 case 数量的最大值也就是1 << 16,pollorder决定了管道的执行顺序,lockorder决定了管道的锁定顺序。
cas1 := (*[1 << 16]scase)(unsafe.Pointer(cas0))
// 它的长度是scase数组的两倍,前半部分分配给pollorder数组,后半部分分配给lockorder数组。
order1 := (*[1 << 17]uint16)(unsafe.Pointer(order0))
ncases := nsends + nrecvs
scases := cas1[:ncases:ncases]
pollorder := order1[:ncases:ncases]
lockorder := order1[ncases:][:ncases:ncases]接下来初始化pollorder数组,它存放的是待执行管道的sacses数组下标
norder := 0
for i := range scases {
cas := &scases[i]
// Omit cases without channels from the poll and lock orders.
if cas.c == nil {
cas.elem = nil // allow GC
continue
}
j := fastrandn(uint32(norder + 1))
pollorder[norder] = pollorder[j]
pollorder[j] = uint16(i)
norder++
}
pollorder = pollorder[:norder]
lockorder = lockorder[:norder]它会遍历整个scases数组,然后通过runtime.fastrandn生成[0, i]之间的随机数,再将它与i交换,过程中会跳过管道为nil的 case,遍历完成后就得到了一个元素被打乱了的pollorder数组,如下图所示

然后对pollorder数组根据管道的地址大小使用堆排序就得到了lockorder数组,再调用runtime.sellock按照顺序将其上锁
func sellock(scases []scase, lockorder []uint16) {
var c *hchan
for _, o := range lockorder {
c0 := scases[o].c
if c0 != c {
c = c0
lock(&c.lock)
}
}
}这里值得注意的是,对管道按照地址大小排序是为了避免死锁,因为 select 操作本身不需要锁允许并发。假设按照pollorder随机顺序加锁,那么考虑下面代码的情况
ch1 := make(chan int)
ch2 := make(chan int)
ch3 := make(chan int)
ch4 := make(chan int)
poll := func() {
select {
case ch1 <- 1:
println(1)
case ch2 <- 2:
println(2)
case ch3 <- 3:
println(3)
case ch4 <- 4:
println(4)
default:
println("default")
}
}
// A
go poll()
// B
go poll()
// C
go poll()三个协程 ABC 都走到了加锁这一步骤,并且它们彼此加锁顺序都是随机的互不相同,有可能造成这样一种情况,如下图所示
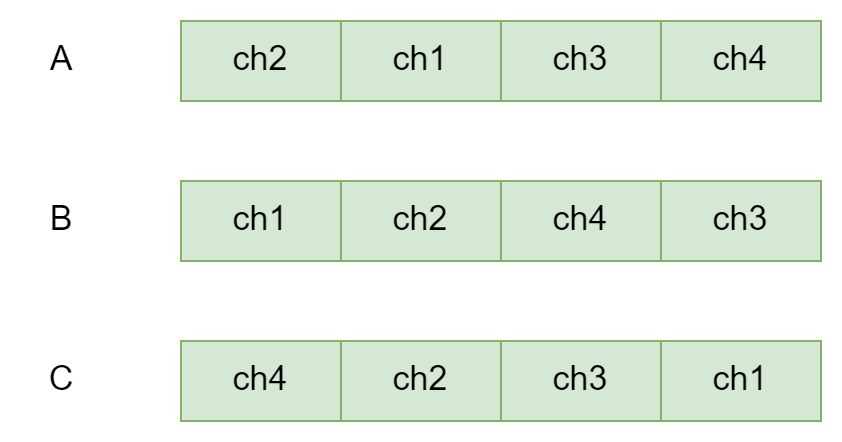
假设 ABC 加锁顺序跟上图一样,那么造成死锁的可能性就非常大,比如 A 会先持有ch2的锁,然后去尝试获取ch1的锁,但假设ch1已经被协程 B 锁住了,协程 B 又会去尝试获取ch2的锁,那么这样就造成了死锁。
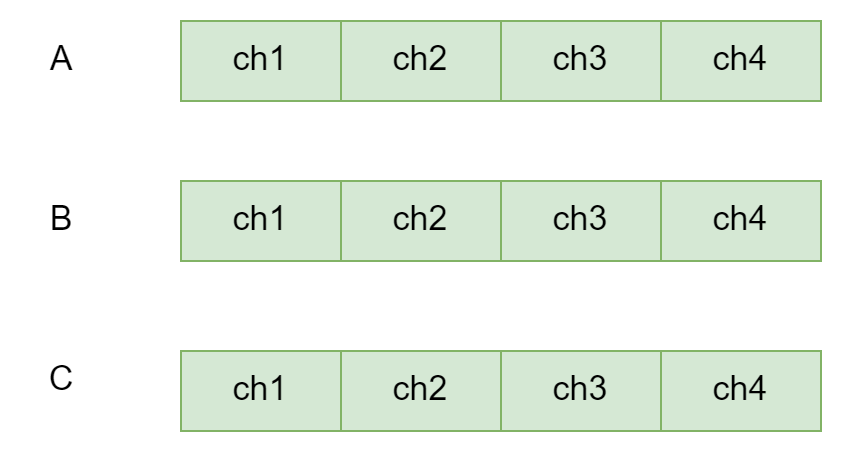
如果所有协程都按照同样的顺序加锁,就不会发送死锁问题,这也是lockorder要按照地址大小来进行排序的根本原因。
上完锁之后,就开始了真正的处理阶段,首先遍历pollorder数组,按照之前打乱的顺序访问管道,逐个遍历找到一个可用的管道
for _, casei := range pollorder {
casi = int(casei)
cas = &scases[casi]
c = cas.c
if casi >= nsends { // 读管道
sg = c.sendq.dequeue()
if sg != nil {
goto recv
}
if c.qcount > 0 {
goto bufrecv
}
if c.closed != 0 {
goto rclose
}
} else { // 写管道
if c.closed != 0 {
goto sclose
}
sg = c.recvq.dequeue()
if sg != nil {
goto send
}
if c.qcount < c.dataqsiz {
goto bufsend
}
}
}可以看到这里对读/写管道做了 6 种情况的处理,下面分别进行讲解。第一种情况,读取管道且有发送方正在等待发送,这里会走到runtime.recv函数,其作用已经讲过了,它最终会唤醒发送方协程,再唤醒之前回调函数会将全部管道解锁。
recv:
// can receive from sleeping sender (sg)
recv(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
recvOK = true
goto retc第二种情况,读取管道,没有发送方正在等待,缓冲区元素数量大于 0,这里会直接从缓冲区中读取数据,其逻辑跟runtime.chanrecv中完全一致,然后解锁。
bufrecv:
recvOK = true
qp = chanbuf(c, c.recvx)
if cas.elem != nil {
typedmemmove(c.elemtype, cas.elem, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
selunlock(scases, lockorder)
goto retc第三种情况,读取管道,但管道已经关闭了,且缓冲区中没有剩余元素,这里会先解锁然后直接返回。
rclose:
selunlock(scases, lockorder)
recvOK = false
if cas.elem != nil {
typedmemclr(c.elemtype, cas.elem)
}
goto retc第四种情况,向已关闭的管道发送数据,这里会先解锁然后panic,
sclose:
selunlock(scases, lockorder)
panic(plainError("send on closed channel"))第五种情况,有接收方正在阻塞等待,这里会调用runitme.send函数,并最终唤醒接收方协程,在唤醒之前回调函数会将全部管道解锁。
send:
send(c, sg, cas.elem, func() { selunlock(scases, lockorder) }, 2)
goto retc第六种情况,没有接收方协程等待,将要发送的数据放入缓冲区,然后解锁。
bufsend:
typedmemmove(c.elemtype, chanbuf(c, c.sendx), cas.elem)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
selunlock(scases, lockorder)
goto retc然后上面所有情况最后都会走入retc这个分支,而它要做的只有返回选中的管道下标casi以及代表着是否读取成功的recvOk。
retc:
return casi, recvOK第七种情况,没有找到可用的管道,且代码中包含default 分支,则解锁管道然后直接返回,这里返回的casi为-1 即表示没有可用的管道。
if !block {
selunlock(scases, lockorder)
casi = -1
goto retc
}最后一种情况,没有找到可用的管道,且代码中不包含default分支,那么当前协程会陷入阻塞状态,在这之前selectgo会将当前协程加入所有监听管道的recvq/sendq队列中
gp = getg()
nextp = &gp.waiting
for _, casei := range lockorder {
casi = int(casei)
cas = &scases[casi]
c = cas.c
sg := acquireSudog()
sg.g = gp
sg.isSelect = true
sg.elem = cas.elem
sg.releasetime = 0
sg.c = c
*nextp = sg
nextp = &sg.waitlink
if casi < nsends {
c.sendq.enqueue(sg)
} else {
c.recvq.enqueue(sg)
}
}这里会将创建若干个sudog并将其和对应的管道链接起来,如下图所示

然后由runtime.gopark阻塞,在阻塞前会将管道解锁,解锁的工作由runtime.selparkcommit函数完成,它被作为回调函数传入了gopark中。
gp.param = nil
// Signal to anyone trying to shrink our stack that we're about
// to park on a channel. The window between when this G's status
// changes and when we set gp.activeStackChans is not safe for
// stack shrinking.
gp.parkingOnChan.Store(true)
gopark(selparkcommit, nil, waitReasonSelect, traceBlockSelect, 1)
gp.activeStackChans = false被唤醒后的第一件事情就是解除sudog与管道的链接
sellock(scases, lockorder)
gp.selectDone.Store(0)
sg = (*sudog)(gp.param)
gp.param = nil
casi = -1
cas = nil
caseSuccess = false
sglist = gp.waiting
// Clear all elem before unlinking from gp.waiting.
for sg1 := gp.waiting; sg1 != nil; sg1 = sg1.waitlink {
sg1.isSelect = false
sg1.elem = nil
sg1.c = nil
}
gp.waiting = nil然后将sudog从之前管道的等待队列中移除
for _, casei := range lockorder {
k = &scases[casei]
if sg == sglist {
// sg has already been dequeued by the G that woke us up.
casi = int(casei)
cas = k
caseSuccess = sglist.success
if sglist.releasetime > 0 {
caseReleaseTime = sglist.releasetime
}
} else {
c = k.c
if int(casei) < nsends {
c.sendq.dequeueSudoG(sglist)
} else {
c.recvq.dequeueSudoG(sglist)
}
}
sgnext = sglist.waitlink
sglist.waitlink = nil
releaseSudog(sglist)
sglist = sgnext
}在上面的过程中一定会找到一个唤醒方协程所处理的管道,然后根据caseSuccess来做出最后的处理。对于写操作而言,sg.success为false代表管道已经关闭了,而且整个 go 运行时也只有close函数会主动将该字段设置为false,这表明当前协程是唤醒方通过close函数唤醒的。对于读操作而言,如果是被发送方唤醒的,数据读取操作也早在被唤醒前由发送方通过runtime.send函数完成了,其值为true,如果是被close函数唤醒的,跟前面一样都是直接返回。
c = cas.c
if casi < nsends {
if !caseSuccess {
goto sclose
}
} else {
recvOK = caseSuccess
}
selunlock(scases, lockorder)
goto retc到此整个 select 的逻辑都大致理清楚了,上面分了好几种情况,可见 select 处理起来还是比较复杂的。