map
map
go 与其它语言不同的是,映射表的支持是由map关键字提供的,而非将其封装为标准库。映射表是一种使用场景非常多的数据结构,底层有着许多的实现方式,最常见的两种方式就是红黑树和哈希表,go 采用的是哈希表实现方式。
提示
map 的实现中涉及到了大量的指针移动操作,所以阅读本文需要unsafe标准库的知识。
内部结构
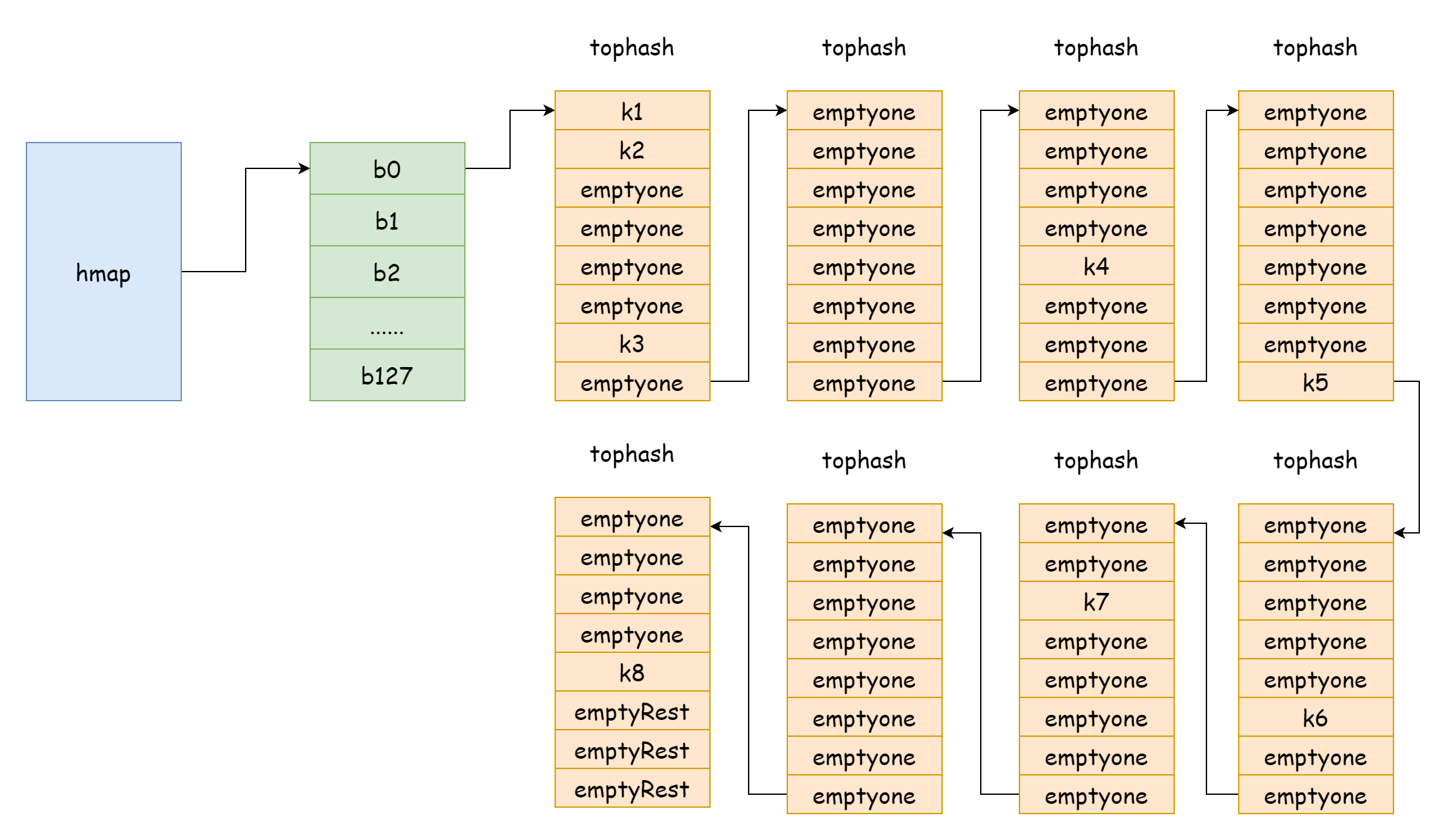
runtime.hmap结构体就是代表着 go 中的map,与切片一样map的内部实现也是结构体。
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}英文注释已经说明的很清晰了,下面对比较重要的字段进行一些简单的解释
count,表示 hamp 中的元素数量,结果等同于len(map)。flags,hmap 的标志位,用于表示 hmap 处于什么状态,有以下几种可能。const ( iterator = 1 // 迭代器正在使用桶 oldIterator = 2 // 迭代器正在使用旧桶 hashWriting = 4 // 一个协程正在写入hmap sameSizeGrow = 8 // 正在等量扩容 )B,hmap 中的哈希桶的数量为1 << B。noverflow,hmap 中溢出桶的大致数量。hash0,哈希种子,在 hmap 被创建时指定,用于计算哈希值。buckets,存放哈希桶数组的指针。oldbuckets,存放 hmap 在扩容前哈希桶数组的指针。extra,存放着 hmap 中的溢出桶,溢出桶指的是就是当前桶已经满了,创建新的桶来存放元素,新创建的桶就是溢出桶。
hamp 中的buckets也就是桶切片指针,在 go 中对应的结构为runtime.bmap,如下所示
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}从上面可以看到它只有一个tophash的字段,该字段是用于存放每个键的高八位,不过实际上来说,bmap的字段不止这些,这是因为map可以存储各种类型的键值对,所以需要在编译时根据类型来推导占用的内存空间,在cmd/compile/internal/reflectdata/reflect.go中的MapBucketType函数的功能就是在编译时构造 bmap,它会进行一系列检查工作,比如 key 的类型是否comparable。
// MapBucketType makes the map bucket type given the type of the map.
func MapBucketType(t *types.Type) *types.Type所以实际上,bmap的结构如下,不过这些字段对我们是不可见的,go 在实际操作中是通过移动 unsafe 指针来进行访问
type bmap struct {
tophash [BUCKETSIZE]uint8
keys [BUCKETSIZE]keyType
elems [BUCKETSIZE]elemType
overflow *bucket
}其中的一些解释如下
tophash,存放每一个键的高八位值,对于一个 tophash 的元素而言,有下面几种特殊的值const ( emptyRest = 0 // 当前元素是空的,并且该元素后面也没有可用的键值了 emptyOne = 1 // 当前元素是空的,但是该元素后面有可用的键值。 evacuatedX = 2 // 扩容时出现,只能出现在oldbuckets中,表示当前元素被搬迁到了新哈希桶数组的上半区 evacuatedY = 3 // 扩容时出现只能出现在oldbuckets中,表示当前元素被搬迁到了新哈希桶数组的下半区 evacuatedEmpty = 4 // 扩容时出现,元素本身就是空的,在搬迁时被标记 minTopHash = 5 // 对于一个正常的键值来说tophash的最小值 )只要是
tophash[i]的值大于minTophash的值,就说明对应下标存在正常的键值。keys,存放指定类型键的数组。elems,存放指定类型值的数组。overflow,指向溢出桶的指针。
既然键值无法通过结构体字段来直接访问,为此 go 事先声明了一个常量dataoffset,它代表的是数据在bmap中的内存偏移量。
const dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)实际上,键值是存放在一个连续的内存地址中,类似于下面这种结构,这样做是为了避免内存对齐带来的空间浪费。
k1,k2,k3,k4,k5,k6...v1,v2,v3,v4,v5,v6...所以对于一个 bmap 而言,指针移动dataoffset后,移动i*sizeof(keyType)就是第 i 个 key 的地址
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))获取第 i 个 value 的地址也是同理
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))hamp中的buckets指针,就是指向的第一个哈希桶的地址,如果想要获取第 i 个哈希桶的地址,偏移量就是i*sizeof(bucket)。
b := (*bmap)(add(h.buckets, i*uintptr(t.BucketSize)))在后续的内容中,这些操作会非常频繁的出现。
哈希
冲突
在 hmap 中,有一个字段extra专门用来存放溢出桶的信息,它会指向存放溢出桶的切片,其结构如下。
type mapextra struct {
// 溢出桶的指针切片
overflow *[]*bmap
// 扩容前旧的溢出桶的指针切片
oldoverflow *[]*bmap
// 指向下一个空闲的溢出桶的指针
nextOverflow *bmap
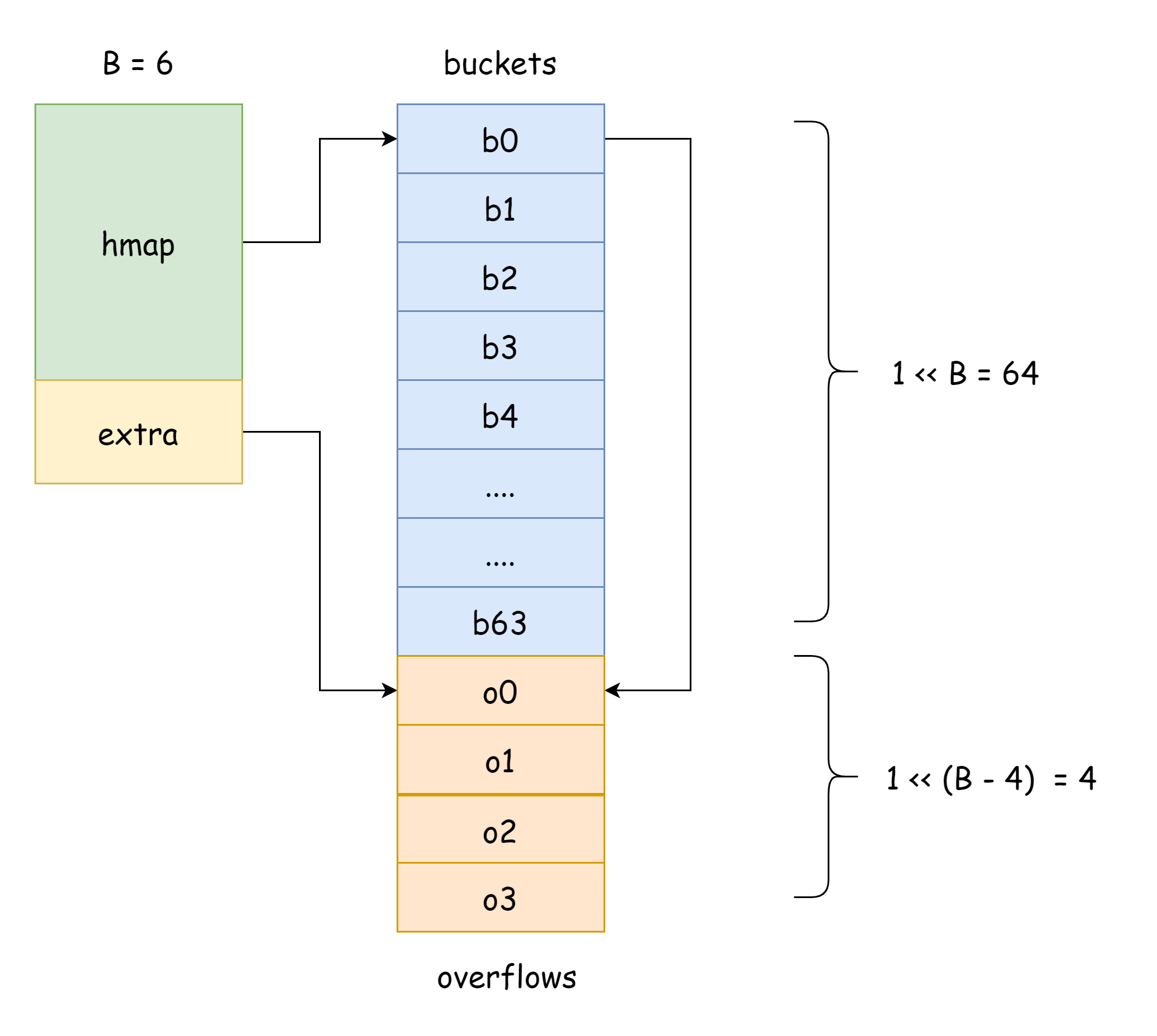
}
提示
在上图中,蓝色部分是哈希桶数组,橙色部分是溢出哈希桶数组,溢出哈希桶下面统称为溢出桶。
上图就可以比较好的展示 hmap 的大致结构,buckets指向哈希桶数组,extra指向溢出桶数组,桶bucket0指向溢出桶overflow0,两种不同的桶分别存放在两个切片中,两种桶的内存都是连续的。当两个键通过哈希后被分配到了同一个 bucket,这种情况就是发生了哈希冲突。go 中解决哈希冲突的方式就是拉链法,当发生冲突的键的数量大于桶的容量后,一般是 8 个,其值取决于internal/abi.MapBucketCount。然后就会创建一个新的桶来存放这些键,而这个桶就叫溢出桶,意为原来的桶装不下了,元素溢出到这个新桶里来了,创建完毕后,哈希桶会有一个指针指向新的溢出桶,这些桶的指针连起来就形成了一个bmap链表。
对于拉链法而言,使用负载因子用于衡量哈希表的冲突情况,其计算公式如下
loadfactor := len(elems) / len(buckets)当负载因子越大时,说明哈希冲突越多,也就是溢出桶的数量越多,那么在读写哈希表时,就需要遍历更多的溢出桶链表,才能找到指定的位置,所以性能就越差。为了改善这种情况,应该增加buckets桶的数量,也就是扩容,对于 hmap 而言,有两种情况会触发扩容
- 负载因子超过阈值
bucketCnt*13/16,其值至少是 6.5。 - 溢出桶数量过多
当负载因子越小时,说明 hmap 的内存利用率低,占用的内存就越大。go 中用于计算负载因子的函数是runtime.overLoadFactor,代码如下
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}其中loadFactorNum和loadFactorDen都是一个常数,bucketshift是计算1 << B,并且已知
loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDen所以化简一下就能得到
count > bucketCnt && uintptr(count) / 1 << B > (bucketCnt * 13 / 16)其中(bucketCnt * 13 / 16)值为 6.5,1 << B就是哈希桶的数量,所以该函数的作用就是计算元素数量除以桶的数量值是否大于负载因子 6.5。
计算
go 内部计算哈希的函数位于runtime/alg.go文件中的f32hash,如下所示,包含了对 NaN 和 0 两种情况的处理。
func f32hash(p unsafe.Pointer, h uintptr) uintptr {
f := *(*float32)(p)
switch {
case f == 0:
return c1 * (c0 ^ h) // +0, -0
case f != f:
return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
default:
return memhash(p, h, 4)
}
}可以看到的是,map 哈希计算方法并不是基于类型,而是基于内存,最终会走到memhash函数,该函数由汇编实现,逻辑位于runtime/asm*.s中。基于内存的哈希值不应该被持久化保存,因为它应该只在运行时被使用,不可能保证每一次运行内存分布都完全一致。
在该文件中还有一个名为typehash的函数,该函数会根据不同类型来计算哈希值,不过 map 并不会使用这个函数来计算哈希。
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr这种实现相比上面那种更慢,但是更通用些,主要用于反射以及编译时的函数生成,比如下面这个函数。
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {
return typehash(t, p, h)
}创建
map 的初始化有两种方式,这一点已经在语言入门中阐述过了,一种是使用关键字map直接创建,另一种是使用make函数,不管用何种方式初始化,最后都是由runtime.makemap来创建 map,该函数签名如下
func makemap(t *maptype, hint int, h *hmap) *hmap其中的参数
t,指的是 map 的类型,不同的类型所需的内存占用不同hint,指的是make函数的第二个参数,map 预计元素的容量。h,指的是hmap的指针,可以为nil。
返回值就是初始化完毕的hmap指针。该函数在初始化过程中有几个主要的工作。首先就是计算预计分配的内存是否会超出最大分配内存,对应如下代码
// 将预计容量与桶类型的内存大小相乘
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
// 数值溢出或者超出了最大分配内存
if overflow || mem > maxAlloc {
hint = 0
}在先前的内部结构中已经提到过,hmap 内部是由桶组成的,在内存利用率最低的情况下,一个桶只有一个元素,占用的内存最多,所以预计的最大内存占用就是元素数量乘以对应类型的内存占用大小。当计算结果数值溢出了,或者超出了最大能分配的内存,就将 hint 置为 0,因为后续需要用 hint 来计算桶数组的容量。
第二步初始化 hmap,并计算出一个随机的哈希种子,对应如下代码
// 初始化
if h == nil {
h = new(hmap)
}
// 获取一个随机的哈希种子
h.hash0 = fastrand()再根据 hint 的值计算出哈希桶的容量,对应的代码如下
B := uint8(0)
// 不断循环直到 hint / 1 << B < 6.5
for overLoadFactor(hint, B) {
B++
}
// 赋值给hmap
h.B = B通过不断循环找到第一个满足(hint / 1 << B) < 6.5的 B 值,将其赋值给 hmap,在知晓了哈希桶的容量后,最后就是为哈希桶分配内存
if h.B != 0 {
var nextOverflow *bmap
// 分配好的哈希桶,和预先分配的空闲溢出桶
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
// 如果预先分配了空闲溢出桶,就指向该溢出桶
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}makeBucketArray函数会根据 B 的值,为哈希桶分配对应大小的内存,以及预先分配空闲的溢出桶,当 B 小于 4 时,就不会创建溢出桶,如果大于 4 那么就会创建2^B-4个溢出桶。对应runtime.makeBucketArray函数中的如下代码
base := bucketShift(b)
nbuckets := base
// 小于4就不会创建溢出桶
if b >= 4 {
// 预计桶的数量加上1 << (b-4)
nbuckets += bucketShift(b - 4)
// 溢出桶所需的内存
sz := t.Bucket.Size_ * nbuckets
// 将内存空间向上取整
up := roundupsize(sz)
if up != sz {
// 不相等就采用up重新计算
nbuckets = up / t.Bucket.Size_
}
}base指的是预计分配桶的数量,nbuckets指的是实际分配桶的数量,它加上了溢出桶的数量。
if base != nbuckets {
// 第一个可用的溢出桶
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.BucketSize)))
// 为了减少跟踪溢出桶的开销,将最后一个可用溢出桶的溢出指针指向哈希桶的头部
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.BucketSize)))
// 最后一个溢出桶指向哈希桶
last.setoverflow(t, (*bmap)(buckets))
}当两者不相等时,就说明分配了额外的溢出桶,nextoverflow指针就是指向的第一个可用的溢出桶。由此可见,哈希桶与溢出桶其实是在同一块连续的内存中,这也是为什么在图中哈希桶数组与溢出桶数组是相邻的。
访问

在语法入门当中讲到过,访问 map 总共有三种方式,如下所示
# 直接访问值
val := dict[key]
# 访问值以及该键是否存在
val, exist := dict[key]
# 遍历map
for key, val := range dict{
}这三种方式所用到的函数都不相同,其中for range遍历 map 最为复杂。
键值
对于前两种方式而言,对应着两个函数,分别是runtime.mapaccess1和runtime.mapaccess2,函数签名如下
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)其中的 key 是指向访问 map 的键的指针,返回的时候也只会返回指针。在访问时,首先需要计算 key 的哈希值,定位 key 在哪个哈希桶,对应代码如下
// 边界处理
if h == nil || h.count == 0 {
if t.HashMightPanic() {
t.Hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
// 防止并发读写
if h.flags&hashWriting != 0 {
fatal("concurrent map read and map write")
}
// 使用指定类型的hasher计算哈希值
hash := t.Hasher(key, uintptr(h.hash0))
// (1 << B) - 1
m := bucketMask(h.B)
// 通过移动指针定位key所在的哈希桶
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))在访问的一开始先进行边界情况处理,并防止 map 并发读写,当 map 处于并发读写状态时,就会发生 panic。再然后计算哈希值,bucketMask函数所干的事就是计算(1 << B) - 1 ,hash & m就等于hash & (1 << B) - 1 ,这是二进制取余操作,等价于hash % (1 << B),使用位运算的好处就是更快。最后三行代码干的事就是将 key 计算得到的哈希值与当前 map 中的桶的数量取余,得到哈希桶的序号,然后根据序号移动指针获取 key 所在的哈希桶指针。
在知晓了 key 在哪个哈希桶后,就可以展开查找了,这部分对应代码如下
// 获取哈希值的高八位
top := tophash(hash)
bucketloop:
// 遍历bmap链表
for ; b != nil; b = b.overflow(t) {
// bmap中的元素
for i := uintptr(0); i < bucketCnt; i++ {
// 将计算得出的top与tophash中的元素进行对比
if b.tophash[i] != top {
// 后续都是空的,没有了。
if b.tophash[i] == emptyRest {
break bucketloop
}
// 不相等就继续遍历溢出桶
continue
}
// 根据i移动指针获取对应下标的键
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
// 处理下指针
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 比对两个键是否相等
if t.Key.Equal(key, k) {
// 如果相等的话,就移动指针返回k对应下标的元素
// 从这行代码就能看出来键值的内存地址是连续的
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// 没找到,返回零值。
return unsafe.Pointer(&zeroVal[0])在定位哈希桶时,是通过取余来定位的,所以 key 在哪个哈希桶取决于哈希值的低位,至于到底是低几位这取决于 B 的大小,而找到了哈希桶后,其中的 tophash 存放的是哈希值的高八位,因为低位取余值都是相同的,这样就不需要去一个个对比 key 是否相等,只对比哈希值高八位就够了。根据先前计算得到的哈希值获取其高八位,在 bmap 中的 tophash 数组一个个对比,如果高八位相等的话,再对比键是否相等,如果键也相等的话就说明找到了元素,不相等就继续遍历 tophash 数组,还找不到就继续遍历溢出桶 bmap 链表,直到 bmap 的tophash[i]为emptyRest退出循环,最后返回对应类型的零值。
mapaccess2 函数与mapaccess1函数逻辑完全一致,仅仅多了一个布尔返回值,用于表示元素是否存在。
遍历
遍历 map 的语法如下
for key, val := range dict {
// do somthing...
}在实际进行遍历时,go 使用了hiter结构体来存放遍历信息,hiter就是hmap interator的简写,意为哈希表迭代器,结构如下所示。
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/reflectdata/reflect.go
// and reflect/value.go to match the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/compile/internal/walk/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}下面对它的一些字段做一些简单的解释
key,elem就是for range遍历时获取到的键值buckets,在初始化迭代器时指定,指向哈希桶的头部bptr,当前正在遍历的 bmapstartBucket,迭代开始时的起始桶序号offset,桶内偏移量,范围[0, bucketCnt-1]B,就是 hmap 的 B 值,i,桶内元素下标wrapped,是否从哈希桶数组末尾回到了头部
在遍历开始前,go 通过runtime.mapiterinit函数来初始化遍历器,然后再通过函数runtime.mapinternext对 map 进行遍历,两者都需要用到hiter结构体,两个函数签名如下。
func mapiterinit(t *maptype, h *hmap, it *hiter)
func mapiternext(it *hiter)对于迭代器初始化而言,首先要获取 map 当前的一个快照,对应如下的代码。
it.t = t
it.h = h
// 记录hmap当前状态的快照,只需要保存B值。
it.B = h.B
it.buckets = h.buckets
if t.Bucket.PtrBytes == 0 {
h.createOverflow()
it.overflow = h.extra.overflow
it.oldoverflow = h.extra.oldoverflow
}后续在迭代时,实际上遍历的是 map 的一个快照,而非实际的 map,所以在遍历过程中添加的元素和桶都不会被遍历到,并且同时并发遍历写入元素,有可能触发fatal。
if h.flags&hashWriting != 0 {
fatal("concurrent map iteration and map write")
}第二步再决定遍历的两个起始位置,第一个是起始桶的位置,第二个桶内的起始位置,这两个都是随机选的,对应如下代码
// r是一个随机数
var r uintptr
if h.B > 31-bucketCntBits {
r = uintptr(fastrand64())
} else {
r = uintptr(fastrand())
}
// r % (1 << B) 得到起始桶的位置
it.startBucket = r & bucketMask(h.B)
// r >> B % 8 得到起始桶内的元素起始位置
it.offset = uint8(r >> h.B & (bucketCnt - 1))
// 记录当前正在遍历的桶序号
it.bucket = it.startBucket通过fastrand()或fastrand64()获取一个随机数,两次取模运算得到桶起始位置和桶内起始位置。
提示
map 虽然不允许同时并发读写,但是允许同时并发遍历。
接下来才真正开始迭代 map,如何对桶进行遍历,以及退出的策略,这部分对应下面的代码
// hmap
h := it.h
// maptype
t := it.t
// 待遍历的桶的位置
bucket := it.bucket
// 待遍历的bmap
b := it.bptr
// 桶内序号i
i := it.i
next:
if b == nil {
// 如果当前桶的位置与起始位置相等,说明是绕了一圈回来,后面的已经遍历过了
// 遍历结束,可以退出了
if bucket == it.startBucket && it.wrapped {
it.key = nil
it.elem = nil
return
}
// 桶下标后移
bucket++
// bucket == 1 << B,就是走到哈希桶数组的末尾了
if bucket == bucketShift(it.B) {
// 从头开始
bucket = 0
it.wrapped = true
}
i = 0
}哈希桶的起始位置选取是随机的,在遍历时,从起始位置向桶切片的末尾逐个迭代,走到1 << B时,然后再从头开始,当再次回到起始位置时,说明已经遍历完毕,然后退出。上面的代码是关于如何在 map 中遍历桶,而下面的代码描述的就是如何在桶内进行遍历。
for ; i < bucketCnt; i++ {
// (i + offset) % 8
offi := (i + it.offset) & (bucketCnt - 1)
// 如果当前元素是空的就跳过
if isEmpty(b.tophash[offi]) || b.tophash[offi] == evacuatedEmpty {
continue
}
// 移动指针获取键
k := add(unsafe.Pointer(b), dataOffset+uintptr(offi)*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 移动指针获取值
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+uintptr(offi)*uintptr(t.ValueSize))
// 处理等量扩容的情况,当键值被疏散到了其它位置后,需要重新去寻找键值。
if (b.tophash[offi] != evacuatedX && b.tophash[offi] != evacuatedY) ||
!(t.ReflexiveKey() || t.Key.Equal(k, k)) {
it.key = k
if t.IndirectElem() {
e = *((*unsafe.Pointer)(e))
}
it.elem = e
} else {
rk, re := mapaccessK(t, h, k)
if rk == nil {
continue
}
it.key = rk
it.elem = re
}
it.bucket = bucket
it.i = i + 1
return
}
// 没找到就去溢出桶里面找
b = b.overflow(t)
i = 0
goto next提示
在上面的扩容判断条件中,有一个表达式可能会让人感到困惑,如下
t.Key.Equal(k, k)之所以要去判断k是否与自身相等,是为了过滤键为Nan的情况,如果一个元素的键是Nan,那么就会无法正常访问该元素,无论是遍历还是直接访问,或者是删除都无法正常进行,因为Nan != Nan永远成立,也就永远无法找到这个键。
首先根据i值和offset值取模运算得到待遍历的桶内下标,通过移动指针获取键值,由于在 map 遍历期间,会有其它的写入操作触发了 map 的扩容,所以实际的键值可能已经不在原来的位置了,在这种情况下就需要使用mapaccessK函数去重新获取实际的键值,该函数签名如下
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)它的功能与mapaccess1函数完全一致,区别在于mapaccessK函数会同时返回 key 值和 value 值。最终获取到了键值以后,将其赋值给迭代器的key,elem,然后更新迭代器的下标,这样就完成了一次迭代,代码执行就回到了for range的代码块中。如果在桶内没有找到,就再去溢出桶里面找,继续重复上面的步骤,直到溢出桶链表遍历完毕后,再继续迭代下一个哈希桶。
修改
修改 map 的语法如下
dict[key] = val在 go 中,对于修改 map 的操作,由runtime.mapassign函数来完成,该函数签名如下
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer其访问过程的逻辑与mapaccess1相同,不过 key 不存在时会为其分配一个位置,如果存在就更新,最后返回元素的指针。在开始时,需要做一些准备工作,这部分对应的代码如下
// 不允许写入为nil的map
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// 禁止同时并发写
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
// 计算key哈希值
hash := t.Hasher(key, uintptr(h.hash0))
// 修改hmap状态
h.flags ^= hashWriting
// 初始化哈希桶
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.Bucket, 1)
}上面的代码主要做了以下几件事
- hmap 状态检查
- 计算 key 的哈希值
- 检查哈希桶是否需要初始化
再之后通过哈希值取模运算得到哈希桶位置,以及 key 的 tophash,代码对应如下
again:
// hash % (1 << B)
bucket := hash & bucketMask(h.B)
// 移动指针获取指定位置的bmap
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
// 计算tophash
top := tophash(hash)现在确定了桶的位置,bmap,tophash,就可以开始查找元素了,这部分代码对应如下
// 待插入的tophash
var inserti *uint8
// 待插入的key值指针
var insertk unsafe.Pointer
// 待插入的value值指针
var elem unsafe.Pointer
bucketloop:
for {
// 遍历桶内的tophash数组
for i := uintptr(0); i < bucketCnt; i++ {
// tophash不相等
if b.tophash[i] != top {
// 如果当前桶内下标是空的,且还没有插入元素,就选取该位置插入
if isEmpty(b.tophash[i]) && inserti == nil {
// 找到了一个合适的位置分配给key
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
}
// 遍历完了就退出循环
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 如果tophash相等的话,则说明key可能已经存在了
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
if t.IndirectKey() {
k = *((*unsafe.Pointer)(k))
}
// 判断key是否相等
if !t.Key.Equal(key, k) {
continue
}
// 如果需要更新key值的话,就将key的内存直接复制到k处
if t.NeedKeyUpdate() {
typedmemmove(t.Key, k, key)
}
// 得到了元素的指针
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// 更新完毕,返回元素指针
goto done
}
// 执行到这里说明没找到key,遍历溢出桶链表,继续找
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// 执行到这里说明key没有存在于map中,但可能已经找到了一个合适的位置分配给key,也可能没有
// 没有找到一个合适的位置分配给key
if inserti == nil {
// 说明当前的哈希桶以及它的溢出桶都满了,那就再分配一个溢出桶
newb := h.newoverflow(t, b)
// 在溢出桶中分配一个位置给key
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.KeySize))
}
// 如果存放的是key指针的话
if t.IndirectKey() {
// 新分配内存,返回的是一个unsafe指针
kmem := newobject(t.Key)
*(*unsafe.Pointer)(insertk) = kmem
// 赋值给insertk,方便后面进行key的内存复制
insertk = kmem
}
// 如果存放的是元素指针
if t.IndirectElem() {
// 分配内存
vmem := newobject(t.Elem)
// 让指针指向vmem
*(*unsafe.Pointer)(elem) = vmem
}
// 将key的内存直接复制到insertk的位置
typedmemmove(t.Key, insertk, key)
*inserti = top
// 数量加一
h.count++
done:
// 执行到这里说明修改过程已经完成了
if h.flags&hashWriting == 0 {
fatal("concurrent map writes")
}
h.flags &^= hashWriting
if t.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
// 返回元素指针
return elem在上述一大段代码中,首先进入 for 循环尝试在哈希桶和溢出桶中去查找,查找的逻辑与mapaccess完全一致,此时有三种可能
- 第一种,在 map 中找到了已经存在的 key,直接跳到
done代码块,返回元素指针 - 第二种,在 map 中找到了一个位置分配给 key 使用,将 key 复制到指定位置,并返回元素指针
- 第三种,所有桶都找完了,没有在 map 中找到可以分配给 key 的位置,创建一个新的溢出桶,并将 key 分配到桶中,然后将 key 复制到指定位置,并返回元素指针
最终得到了元素指针后,就可以赋值了,不过这部分操作并不由mapassign函数来完成,它只负责返回元素指针,赋值操作是在编译器期间插入的,在代码里面看不见,但是编译后的代码可以看见,假设有下面的代码
func main() {
dict := make(map[string]string, 100)
dict["hello"] = "world"
}通过命令如下命令得到汇编代码
go tool compile -S -N -l main.go关键的地方就在这部分
0x004e 00078 LEAQ type:map[string]string(SB), AX
0x0055 00085 CALL runtime.mapassign_faststr(SB)
0x005a 00090 MOVQ AX, main..autotmp_2+40(SP)
0x0083 00131 LEAQ go:string."world"(SB), CX
0x008a 00138 MOVQ CX, (AX)可以看到调用了runtime.mapassign_faststr,其逻辑与mapassign完全相似,LEAQ go:string."world"(SB), CX就是将字符串的地址存储到CX上,MOVQ CX, (AX)再将其存储到了AX上,于是就完成了元素的赋值。
删除
在 go 中,要想删除一个 map 的元素,只能使用内置函数delete,如下
delete(dict, "abc")其内部调用的是runtime.mapdelete函数,该函数签名如下
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer)它会删除 map 中指定 key 的元素,不管元素是否存在于 map 中,它都不会有任何反应。函数开头做准备工作的逻辑都是类似的,无非就是下面几件事
- hmap 状态检查
- 计算 key 的哈希值
- 定位哈希桶
- 计算 tophash
前面有很多重复的内容,就不再赘述了,这里只关注它删除的逻辑,对应的部分代码如下。
bOrig := b
search:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 没找到就退出循环
if b.tophash[i] == emptyRest {
break search
}
continue
}
// 移动指针找到key的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.KeySize))
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
if !t.Key.Equal(key, k2) {
continue
}
// 删除key
if t.IndirectKey() {
*(*unsafe.Pointer)(k) = nil
} else if t.Key.PtrBytes != 0 {
memclrHasPointers(k, t.Key.Size_)
}
// 移动指针找到元素的位置
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.KeySize)+i*uintptr(t.ValueSize))
// 删除元素
if t.IndirectElem() {
*(*unsafe.Pointer)(e) = nil
} else if t.Elem.PtrBytes != 0 {
memclrHasPointers(e, t.Elem.Size_)
} else {
memclrNoHeapPointers(e, t.Elem.Size_)
}
notLast:
// 数量减一
h.count--
// 重置哈希种子,减小冲突发生概率
if h.count == 0 {
h.hash0 = fastrand()
}
break search
}
}通过上面的代码可以看到,查找的逻辑跟前面的操作是几乎完全一致的,找到元素,然后删除,hmap 记录的数量减一,当数量减为 0 时,就重置哈希种子。
另一个要注意的点就是,在删除完元素后,需要修改当前下标的 tophash 状态,这部分对应的代码如下。当 i 在桶末尾时,判断根据下一个溢出桶来判断当前元素是否是最后一个可用元素,否则的话就直接查看相邻元素的哈希状态。如果当前元素不是最后一个可用的,就将状态置为emptyOne。
// 将当前tophash标记为空
b.tophash[i] = emptyOne
// 如果在tophash末尾
if i == bucketCnt-1 {
// 溢出桶不为空,且溢出桶内有元素,说明当前元素不是最后一个
if b.overflow(t) != nil && b.overflow(t).tophash[0] != emptyRest {
goto notLast
}
} else {
// 相邻元素不为空
if b.tophash[i+1] != emptyRest {
goto notLast
}
}如果元素确实是最后一个元素的话,就需要修正一下桶链表中部分桶的 tophash 数组的值,否则的话后续遍历时会导致无法在正确的位置退出。在 map 创建溢出桶的时候讲述过,go 为了减少追踪溢出桶的成本,最后一个溢出桶的overflow指针就是指向头部的哈希桶,所以它实际上是一个单向环形链表,链表的“头部”就是哈希桶。而这里的b是查找过后的b,很可能是链表中间的某一个溢出桶,逆序遍历环形链表查找最后一个存在的元素。尽管代码写的是正序遍历,由于链表是一个环,它不断正序遍历直到当前溢出桶的前一个为止,从结果上来说确实是逆序的。再然后逆序遍历桶中的 tophash 数组,将状态为emptyOne的元素更新为emptyRest,直到找到最后一个存在的元素。为避免无限陷入在环中,当回到了最开始的桶时,也就是bOrig,说明此时链表内已经没有可用的元素了,就可以退出循环了。
// 执行到这里说明当前元素后面没有元素了
// 不断的倒序遍历bmap链表,倒序遍历桶内的tophash
// 将状态为emptyOne的更新为emptyRest
for {
b.tophash[i] = emptyRest
if i == 0 {
if b == bOrig {
break
}
c := b
// 找到当前bmap链表的前一个
for b = bOrig; b.overflow(t) != c; b = b.overflow(t) {
}
i = bucketCnt - 1
} else {
i--
}
if b.tophash[i] != emptyOne {
break
}
}清空
在go1.21版本中,新增了内置函数clear,可以用于清空 map 中的所有元素,语法如下
clear(dict)其内部调用了runtime.mapclear函数,它负责删除 map 中的所有元素,其函数签名如下
func mapclear(t *maptype, h *hmap)该函数的逻辑并不复杂,首先需要将整个 map 标记为空,对应的代码如下。
// 遍历每一个桶以及溢出桶,将所有的tophash元素置为emptyRest
markBucketsEmpty := func(bucket unsafe.Pointer, mask uintptr) {
for i := uintptr(0); i <= mask; i++ {
b := (*bmap)(add(bucket, i*uintptr(t.BucketSize)))
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
b.tophash[i] = emptyRest
}
}
}
}
markBucketsEmpty(h.buckets, bucketMask(h.B))上面代码做的事情就是遍历每一个桶,将桶中的 tophash 数组的元素都置为emptyRest,将 map 标记为空,这样就能阻止迭代器继续迭代,然后再清空 map,对应的代码如下。
// 重置哈希种子
h.hash0 = fastrand()
// 重置extra结构体
if h.extra != nil {
*h.extra = mapextra{}
}
// 这个操作会清除原来buckets的内存,并重新分配新的桶
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
if nextOverflow != nil {
// 分配新的空闲溢出桶
h.extra.nextOverflow = nextOverflow
}通过makeBucketArray清除之前的桶的内存,然后新分配一个,这样一来就完成了桶的清除,除此之外还有一些细节,比如说将count置 0,还有其它的一些操作就不过多赘述。
扩容
在之前的所有操作中,为了更关注其本身的逻辑,所以屏蔽了很多跟扩容有关内容,这样会简单很多。扩容的逻辑其实比较复杂,放在最后就是不希望产生干扰,那么现在就来看看 go 是如何对 map 进行扩容的,前面已经提到过,触发扩容有两个条件:
- 负载因子超过 6.5
- 溢出桶的数量过多
判断负载因子是否超过阈值的函数是runtime.overLoadFactor函数,在哈希冲突部分已经阐述过,而判断溢出桶的数量是否过多的函数是runtime.tooManyOverflowBuckets,其工作原理也很简单,代码如下
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}上面的代码可以简化成如下表达式,一眼就能看懂。
overflow >= 1 << (min(15,B) % 16)在这里,go 对于 too many 的定义是:溢出桶的数量跟哈希桶的数量差不多,如果阈值低了,就会做多余的工作,如果阈值高了,那么在扩容的时候就会占用大量的内存。在修改和删除元素时就有可能触发扩容,判断是否需要扩容的代码如下。
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}可以看到的就是这三个条件限制
- 当前不能正在扩容
- 负载因子小于 6.5
- 溢出桶数量不能过多
负责扩容的函数自然就是runtime.hashGrow,其函数签名如下
func hashGrow(t *maptype, h *hmap)实际上,扩容也分种类,根据不同条件触发的扩容其类型也不同,分为以下两种
- 增量扩容
- 等量扩容
增量扩容
当负载因子过大时,即元素数量较大于哈希桶的数量,当哈希冲突比较严重的时候,会形成很多溢出桶链表,这样会导致 map 读写性能下降,因为需要查找一个元素遍历更多的溢出桶链表,而遍历的时间复杂度是 O(n),哈希表查找的时间复杂度主要取决于哈希值的计算时间和遍历的时间,当遍历的时间远小于计算哈希的时间时,查找的时间复杂度才能称为 O(1)。倘若哈希冲突比较频繁,过多 key 都被分配到了同一个哈希桶,溢出桶链表过长导致遍历时间增大,就会导致查找时间增大,而增删改操作都需要先进行查找操作,这样一来的话就会导致整个 map 的性能严重下降。
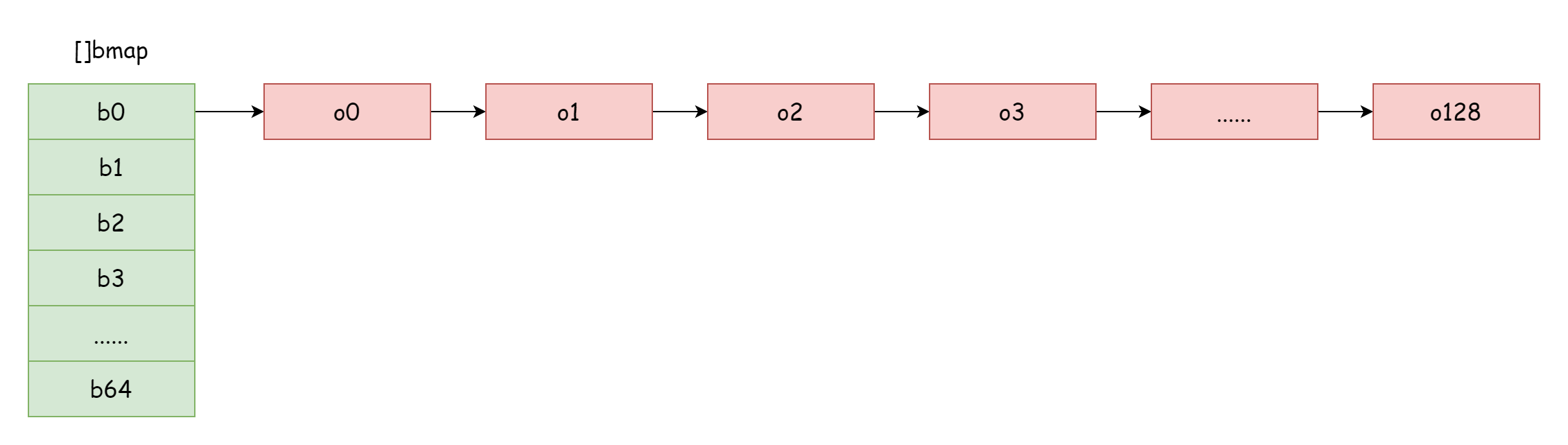
像图中这种比较极端的情况,查找的时间复杂度基本上跟 O(n)没啥区别了。面对这种情况,解决办法就是新增更多的哈希桶,避免形成过长的溢出桶链表,这种方法也被称为增量扩容。
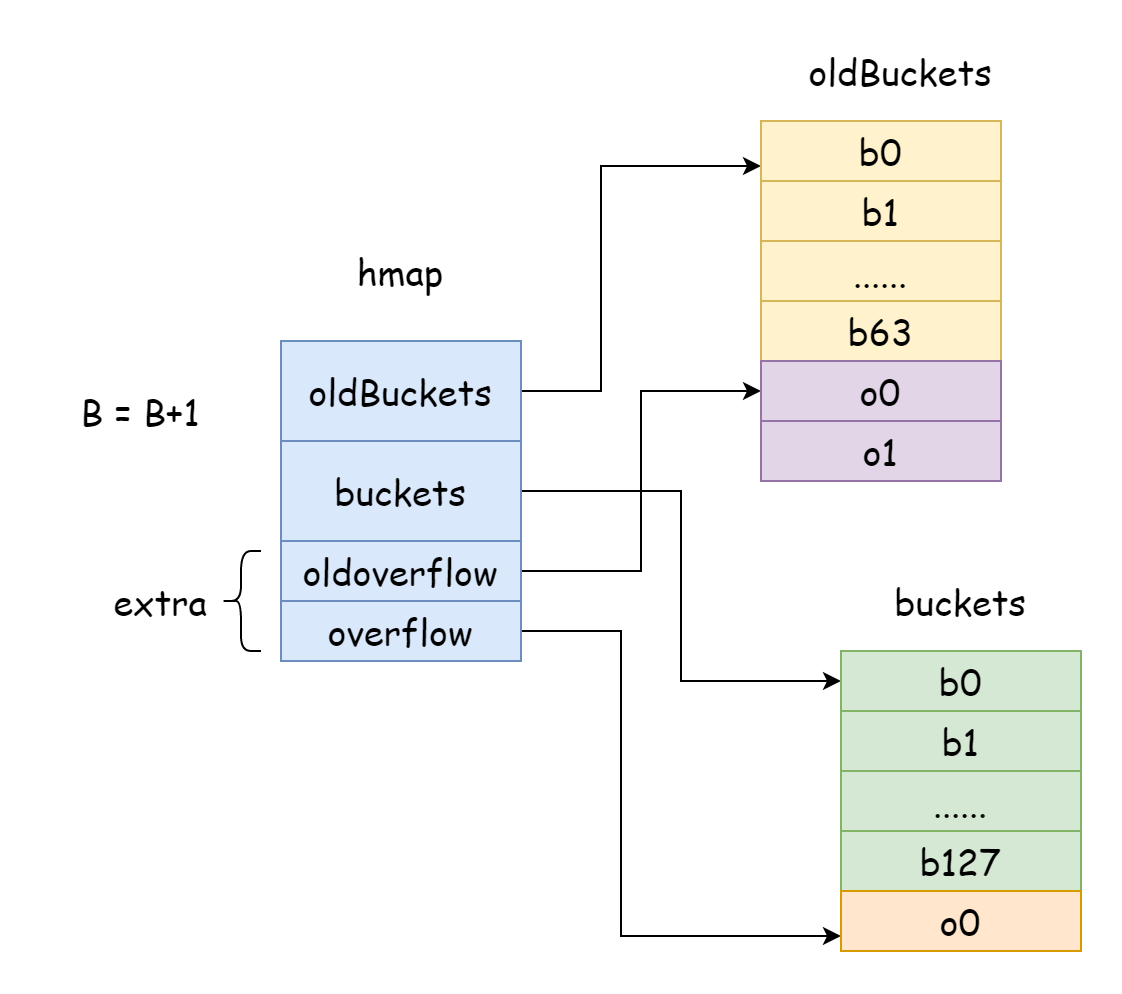
在 go 中,增量扩容每次都会将 B 加一,也就是哈希桶的规模每次扩大一倍。扩容后,需要将旧数据搬迁到新的 map 中,倘若 map 中的元素数量以千万甚至亿计,一次性全部搬迁完的话耗时会很久,所以 go 采用的是逐步搬迁的策略,为此,go 会将 hamp 中的oldBuckets指向原来的哈希桶数组,表示这是旧数据,然后创建更大容量的哈希桶数组,让hmap中的buckets指向新的哈希桶数组,然后在每一次修改和删除元素时,将部分元素搬迁从旧桶搬到新桶,直到搬迁完毕,旧桶的内存才会被释放掉。
func hashGrow(t *maptype, h *hmap) {
// 差值
bigger := uint8(1)
// 旧桶
oldbuckets := h.buckets
// 新的哈希桶
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// B+bigger
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
// 溢出桶也要指定旧桶和新桶
if h.extra != nil && h.extra.overflow != nil {
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
}上面的代码做的事情就是创建大一倍容量的新哈希桶,然后指定哈希新旧桶的引用,以及溢出新旧桶的引用,而实际的搬迁工作并不由hashGrow函数来完成,它只负责指定新旧桶,并更新hmap的一些状态。这些工作实际上是由runtime.growWork函数完成的,其函数签名如下
func growWork(t *maptype, h *hmap, bucket uintptr)它会在mapassign函数和mapdelete函数中,以如下的形式被调用,其作用就是如果当前 map 正在扩容中,就进行一次部分搬迁工作。
if h.growing() {
growWork(t, h, bucket)
}在进行修改和删除操作时,需要判断当前是否处于扩容中,这主要由hmap.growing方法来完成,内容很简单,就是判断oldbuckets是否为不为空,对应代码如下。
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}来看看growWork函数都干了些什么。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// bucket % 1 << (B-1)
evacuate(t, h, bucket&h.oldbucketmask())
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}其中bucket&h.oldbucketmask()操作是计算得到旧桶的位置,确保将要搬迁的是当前桶的旧桶。从函数中可以看到真正负责搬迁工作的是runtime.evacuate函数,其中用到了evaDst结构体用来表示搬迁目的地,主要作用是在搬迁的过程中迭代新桶,它的结构如下。
type evacDst struct {
b *bmap // 搬迁目的地的新桶
i int // 桶内下标
k unsafe.Pointer // 指向新键目的地的指针
e unsafe.Pointer // 指向新值目的地的指针
}在搬迁开始之前,go 会分配两个evacDst结构体,一个指向新哈希桶的上半区,另一个指向新哈希桶的下半区,对应的代码如下
// 定位旧桶中指定的哈希桶
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.BucketSize)))
// 旧桶的长度 = 1 << (B - 1)
newbit := h.noldbuckets()
var xy [2]evacDst
x := &xy[0]
// 指向新桶的上半区
x.b = (*bmap)(add(h.buckets, oldbucket*uintptr(t.BucketSize)))
x.k = add(unsafe.Pointer(x.b), dataOffset)
x.e = add(x.k, bucketCnt*uintptr(t.KeySize))
// 判断是不是等量扩容
if !h.sameSizeGrow() {
y := &xy[1]
// 指向新桶的下半区
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}旧桶的搬迁目的地是两个新桶,搬迁后,桶中的部分数据会在上半区,另一部分的数据会在下半区,这样做是希望扩容后的数据能够更加均匀的分布,分布的越均匀,map 的查找性能就会越好。go 如何将数据搬迁到两个新桶中,对应着下面的代码。
// 遍历溢出桶链表
for ; b != nil; b = b.overflow(t) {
// 拿到每个桶的第一键值对
k := add(unsafe.Pointer(b), dataOffset)
e := add(k, bucketCnt*uintptr(t.KeySize))
// 遍历桶中的每一个键值对
for i := 0; i < bucketCnt; i, k, e = i+1, add(k, uintptr(t.KeySize)), add(e, uintptr(t.ValueSize)) {
top := b.tophash[i]
// 如果是空的就跳过
if isEmpty(top) {
b.tophash[i] = evacuatedEmpty
continue
}
// 新哈希桶不应该处于搬迁状态
// 否则的话肯定是出问题了
if top < minTopHash {
throw("bad map state")
}
k2 := k
if t.IndirectKey() {
k2 = *((*unsafe.Pointer)(k2))
}
// 该变量决定了当前键值对被搬迁到上半区还是下半区
// 它的值只能是0或1
var useY uint8
if !h.sameSizeGrow() {
// 重新计算哈希值
hash := t.Hasher(k2, uintptr(h.hash0))
// 处理k2 != k2的特殊情况,
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}
// 检查常量的值
if evacuatedX+1 != evacuatedY || evacuatedX^1 != evacuatedY {
throw("bad evacuatedN")
}
// 更新旧桶的tophash,表示当前元素已被搬迁
b.tophash[i] = evacuatedX + useY // evacuatedX + 1 == evacuatedY
// 指定搬迁目的地
dst := &xy[useY] // evacuation destination
// 新桶容量不够用了建个溢出桶
if dst.i == bucketCnt {
dst.b = h.newoverflow(t, dst.b)
dst.i = 0
dst.k = add(unsafe.Pointer(dst.b), dataOffset)
dst.e = add(dst.k, bucketCnt*uintptr(t.KeySize))
}
dst.b.tophash[dst.i&(bucketCnt-1)] = top // mask dst.i as an optimization, to avoid a bounds check
// 复制键
if t.IndirectKey() {
*(*unsafe.Pointer)(dst.k) = k2 // copy pointer
} else {
typedmemmove(t.Key, dst.k, k) // copy elem
}
// 复制值
if t.IndirectElem() {
*(*unsafe.Pointer)(dst.e) = *(*unsafe.Pointer)(e)
} else {
typedmemmove(t.Elem, dst.e, e)
}
// 后移新桶目的指针,为下一个键值做准备
dst.i++
dst.k = add(dst.k, uintptr(t.KeySize))
dst.e = add(dst.e, uintptr(t.ValueSize))
}
}从上面的代码可以看到,go 会遍历旧桶链表中的每一个桶中的每一个元素,将其中的数据搬到新桶中,决定数据到底是去上半区还是下半区取决于重新计算后的哈希值
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}在搬迁后,会将当前元素的 tophash 置为evacuatedX或evacuated,如果在扩容的过程中尝试查找数据,通过此状态就可以得知数据已经被搬迁,就知道要去新桶里面找对应的数据。这部分逻辑对应runtime.mapaccess1函数中的如下代码。
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
// 如果旧桶已经被搬迁了就不找了
if !evacuated(oldb) {
b = oldb
}
}在访问元素时,如果当前正处于扩容状态,会先去尝试去旧桶里面查找,如果旧桶已经被搬迁了就不去旧桶里面找。回到搬迁这块,此时已经确定了搬迁的目的地,接下来要做就是将数据复制到新桶中,然后让evacDst结构体指向下一个目的地。
dst := &xy[useY]
dst.b.tophash[dst.i&(bucketCnt-1)] = top
typedmemmove(t.Key, dst.k, k)
typedmemmove(t.Elem, dst.e, e)
if h.flags&oldIterator == 0 && t.Bucket.PtrBytes != 0 {
b := add(h.oldbuckets, oldbucket*uintptr(t.BucketSize))
ptr := add(b, dataOffset)
n := uintptr(t.BucketSize) - dataOffset
memclrHasPointers(ptr, n)
}这样操作直到当前桶全部搬迁完毕,然后 go 就会将当前旧桶键值数据全部内存清除,只留下一个哈希桶 tophash 数组(留下是因为后续要靠 tophash 数组判断搬迁状态),旧桶中的溢出桶内存由于不再被引用后续会被 GC 回收掉。hmap中有一个字段nevacuate用来记录搬迁进度,每搬完一个旧的哈希桶,就会加一,当它的值与旧桶的数量相等时,就说明整个 map 的扩容已经完成了,接下来就由runtime.advanceEvacuationMark函数进行扩容的收尾工作。
func advanceEvacuationMark(h *hmap, t *maptype, newbit uintptr) {
h.nevacuate++
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
if h.nevacuate == newbit { // newbit = len(oldbuckets)
h.oldbuckets = nil
if h.extra != nil {
h.extra.oldoverflow = nil
}
h.flags &^= sameSizeGrow
}
}它会统计已搬迁数量并确认是否与旧桶数量相等,相等的话就清除对于所有旧桶和旧溢出桶的引用,至此扩容完毕。
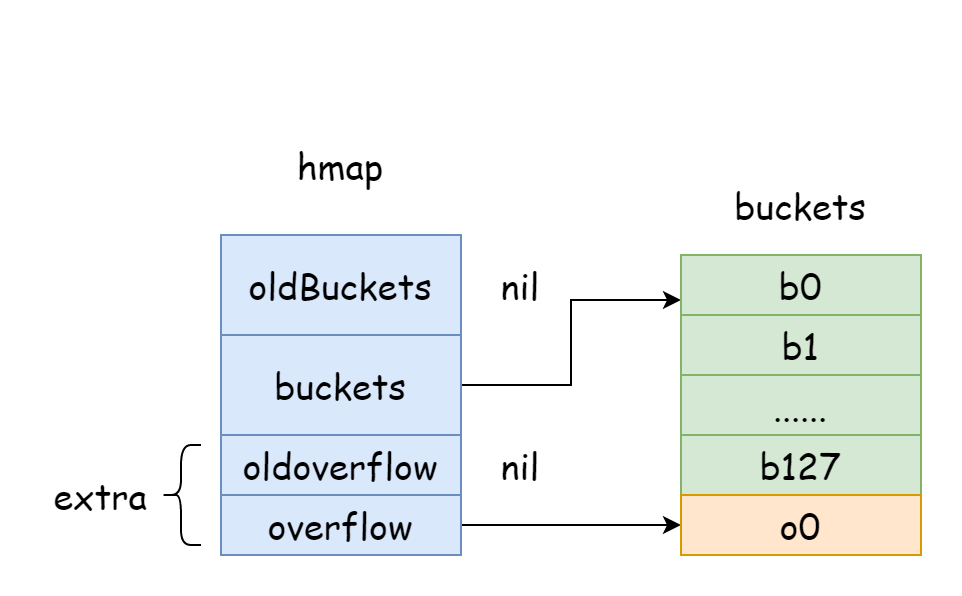
在growWork函数中,总共调用了两次evacuate函数,第一次是搬当前正在访问桶的旧桶,第二次是搬h.nevacuate所指向的旧桶,总共搬了两次,说明逐步搬迁时,每一次都会搬两个桶。
等量扩容
前面提到过,等量扩容的触发条件是溢出桶数量过多,假如 map 先是添加了大量的元素,然后又大量删除元素,这样一来可能很多桶都是空的,可能有些桶有很多的元素,数据分布十分不均匀,有相当多的溢出桶都是空的,占用了不少的内存。为了解决这类问题,就需要创建一个同等容量的新 map,重新分配一次哈希桶,这个过程就叫等量扩容。所以其实并不是扩容操作,只是将所有元素二次分配使数据分布更加均匀,等量扩容操作是糅合在增量扩容操作中的,其逻辑与增量扩容完全一致,新旧 map 容量完全相等。
在hashGrow函数中,如果负载因子没有超过阈值,进行的就是等量扩容,go 更新h.flags的状态为sameSizeGrow,h.B也不会加一,所以新创建的哈希桶容量也不会有变化,对应代码如下。
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)在evacuate函数中,刚开始创建eavcDst结构体时,如果是等量扩容的话就只会创建一个结构体指向新桶,对应代码如下。
if !h.sameSizeGrow() {
y := &xy[1]
y.b = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.BucketSize)))
y.k = add(unsafe.Pointer(y.b), dataOffset)
y.e = add(y.k, bucketCnt*uintptr(t.KeySize))
}并且在搬迁元素的时候,等量扩容不会重新计算哈希值,也没有上下半区的选择
if !h.sameSizeGrow() {
// 重新计算哈希值
hash := t.Hasher(k2, uintptr(h.hash0))
// 处理k2 != k2的特殊情况,
if h.flags&iterator != 0 && !t.ReflexiveKey() && !t.Key.Equal(k2, k2) {
useY = top & 1
top = tophash(hash)
} else {
// hash % 1 << (B - 1)
if hash&newbit != 0 {
useY = 1
}
}
}除了这些,其它的逻辑与增量扩容完全一致。经过等量扩容哈希桶重新分配过后,溢出桶的数量就会减少,旧的溢出桶都会被 GC 回收掉。