memory
memory
与传统的 c/c++不同,go 是一个 gc 语言,大多数情况下内存的分配和销毁由 go 来进行自动管理,一个对象的内存应该被分配到栈上还是堆上由编译器来进行决定,基本上不需要用户参与内存管理,用户要做的仅仅就是使用内存。在 go 中堆内存管理主要有两个大的组件,内存分配器负责堆内存的分配,垃圾回收器负责回收释放无用的堆内存,本文主要讲的就是内存分配器的工作方式,go 内存分配器很大程度上受到了谷歌的 TCMalloc 内存分配器的影响。
分配器
在 go 中有两种内存分配器,一种是线性分配器,另一种就是链式分配。
线性分配
线性分配器对应着runtime.linearAlloc结构体,如下所示
type linearAlloc struct {
next uintptr // next free byte
mapped uintptr // one byte past end of mapped space
end uintptr // end of reserved space
mapMemory bool // transition memory from Reserved to Ready if true
}该分配器会向操作系统预先申请一片连续的内存空间,next指向可使用的内存地址,end指向内存空间的末尾地址,大概可以理解为下图。
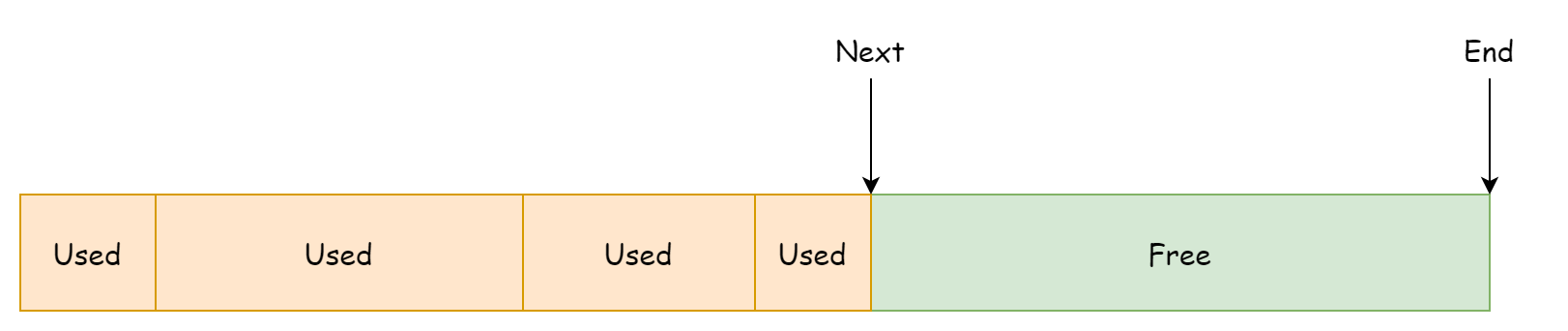
线性分配器的内存分配方式非常好理解,根据要申请的内存大小检查是否有足够的剩余空间来容纳,如果足够的话就更新next字段并返回剩余空间的起始地址,代码如下。
func (l *linearAlloc) alloc(size, align uintptr, sysStat *sysMemStat) unsafe.Pointer {
p := alignUp(l.next, align)
if p+size > l.end {
return nil
}
l.next = p + size
return unsafe.Pointer(p)
}这种分配方式的优点就是快速和简单,缺点也相当明显,就是无法重新利用已释放的内存,因为next字段只会指向剩余的空间内存地址,对于先前已使用后被释放的内存空间则无法感知,这样做会造成很大的内存空间浪费,如下图所示。
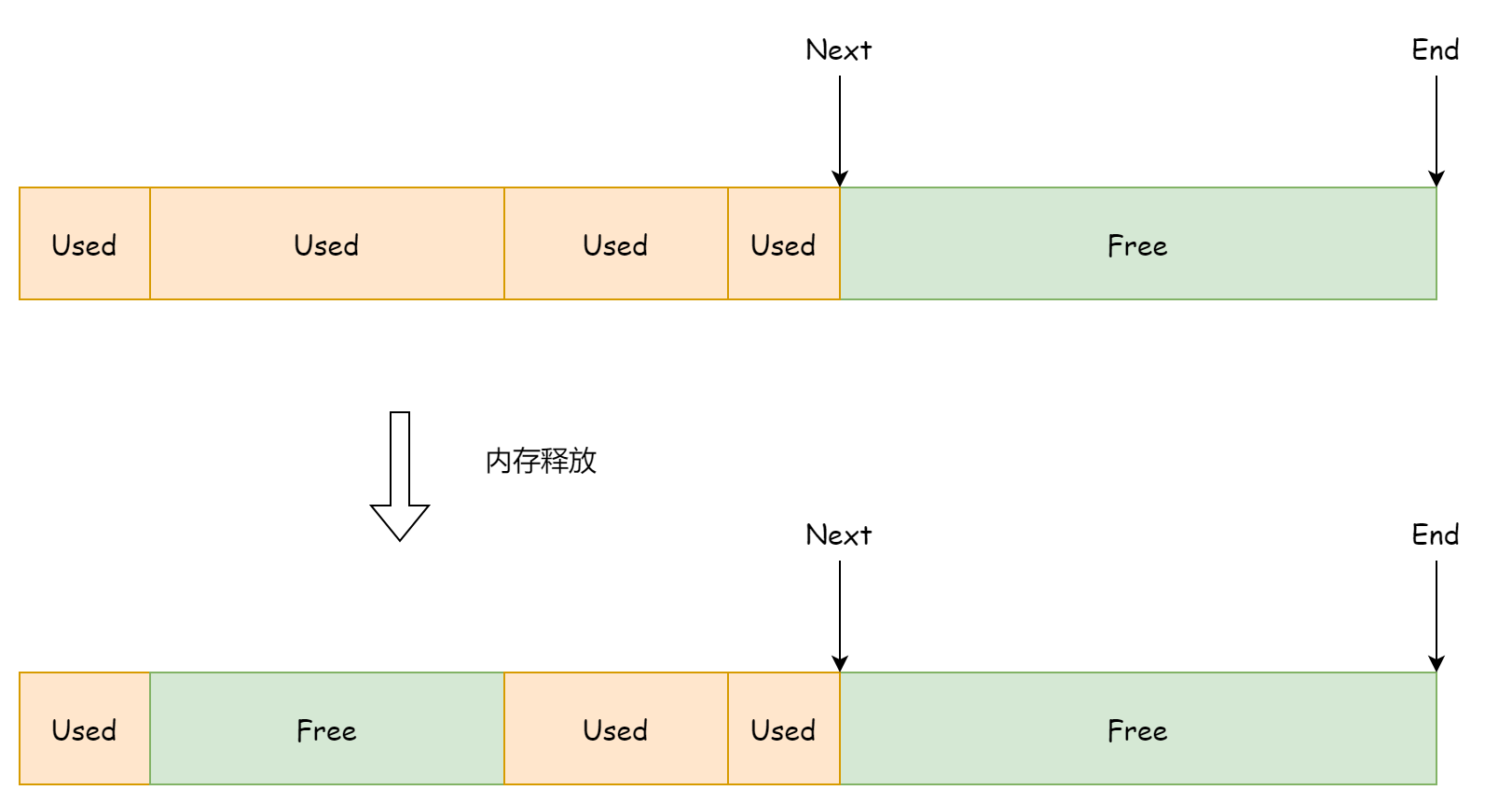
所以线性分配并不是 go 中主要的分配方式,它只在 32 位机器上作为内存预分配的功能来使用。
链式分配
链式分配器器对应着结构体runtime.fixalloc,链式分配器分配的内存不是连续的,以单向链表的形式存在。链式分配器由若干个固定大小的内存块组成,而每一个内存块由若干个固定大小的内存片组成,每一次进行内存分配时,都会使用一个固定大小的内存片。
type fixalloc struct {
size uintptr
first func(arg, p unsafe.Pointer) // called first time p is returned
arg unsafe.Pointer
list *mlink
chunk uintptr // use uintptr instead of unsafe.Pointer to avoid write barriers
nchunk uint32 // bytes remaining in current chunk
nalloc uint32 // size of new chunks in bytes
inuse uintptr // in-use bytes now
stat *sysMemStat
zero bool // zero allocations
}
type mlink struct {
_ sys.NotInHeap
next *mlink
}它的字段不像线性分配器一样简单易懂,这里简单介绍一下重要的
size,指的是每次内存分配时使用多少的内存。list,指向可复用内存片的头节点,每一片内存空间的大小由size决定。chunk,指向当前正在使用的内存块中的空闲地址nchunk,当前内存块的剩余可用字节数nalloc, 内存块的大小,固定为 16KB。inuse,总共已使用了多少字节的内存zero,在复用内存块时,是否将内存清零
链式分配器持有着当前内存块和可复用内存片的引用,每一个内存块的大小都固定为 16KB,这个值在初始化时就被设置好了。
const _FixAllocChunk = 16 << 10
func (f *fixalloc) init(size uintptr, first func(arg, p unsafe.Pointer), arg unsafe.Pointer, stat *sysMemStat) {
if size > _FixAllocChunk {
throw("runtime: fixalloc size too large")
}
if min := unsafe.Sizeof(mlink{}); size < min {
size = min
}
f.size = size
f.first = first
f.arg = arg
f.list = nil
f.chunk = 0
f.nchunk = 0
f.nalloc = uint32(_FixAllocChunk / size * size)
f.inuse = 0
f.stat = stat
f.zero = true
}内存块的分布如下图所示,图中的内存块是按照创建时间的先后来进行排列的,实际上它们的地址是不连续的。
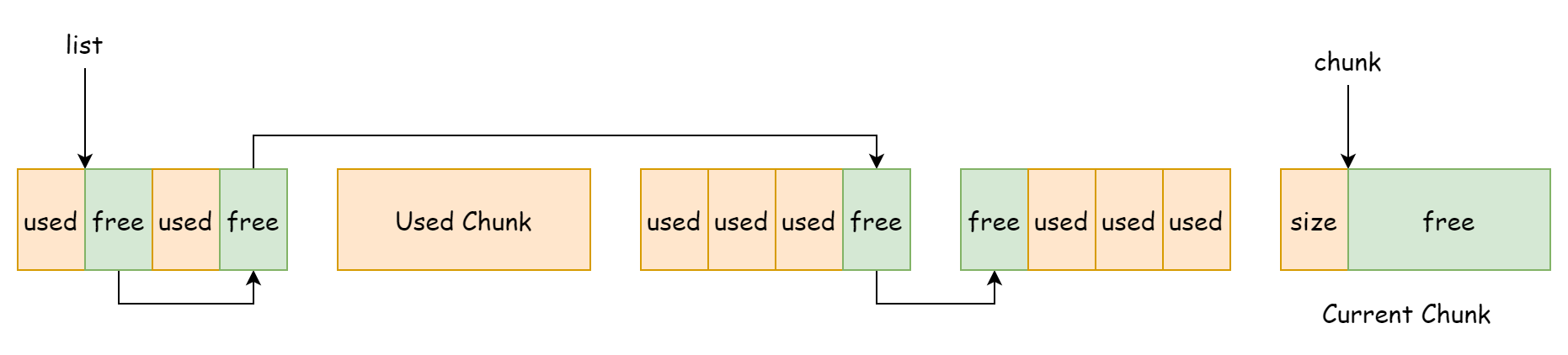
链式分配器每一次分配的内存大小也是固定的,由fixalloc.size来决定,在分配时会首先检查是否有可复用的内存块,如果有的话则优先使用复用内存块,然后才会去使用当前的内存块,如果当前的内存块的剩余空间不足以容纳就会创建一个新的内存块,这部分逻辑对应如下代码。
func (f *fixalloc) alloc() unsafe.Pointer {
if f.size == 0 {
print("runtime: use of FixAlloc_Alloc before FixAlloc_Init\n")
throw("runtime: internal error")
}
if f.list != nil {
v := unsafe.Pointer(f.list)
f.list = f.list.next
f.inuse += f.size
if f.zero {
memclrNoHeapPointers(v, f.size)
}
return v
}
if uintptr(f.nchunk) < f.size {
f.chunk = uintptr(persistentalloc(uintptr(f.nalloc), 0, f.stat))
f.nchunk = f.nalloc
}
v := unsafe.Pointer(f.chunk)
if f.first != nil {
f.first(f.arg, v)
}
f.chunk = f.chunk + f.size
f.nchunk -= uint32(f.size)
f.inuse += f.size
return v
}链式分配器的优点正是它可以复用被释放的内存,复用内存的基本单位是一个固定大小的内存片,其大小由fixalloc.size决定,在释放内存时,链式分配器会将该内存片作为头结点添加到空闲内存片链表中,代码如下所示
func (f *fixalloc) free(p unsafe.Pointer) {
f.inuse -= f.size
v := (*mlink)(p)
v.next = f.list
f.list = v
}内存组件
go 中的内存分配器主要由msapn,heaparena,mcache,mcentral,mheap这几个组件构成,它们之间层层作用,管理着整个 go 的堆内存。
mspan
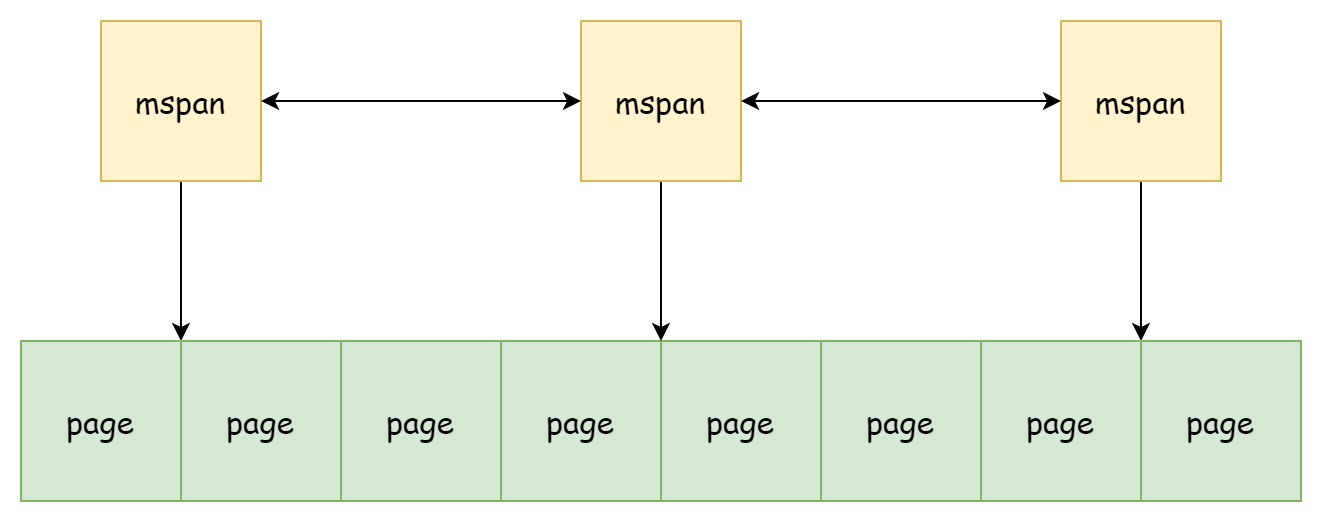
runtime.mspan是 go 内存分配中基本的单位,其结构如下
type mspan struct {
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
freeindex uintptr
spanclass spanClass // size class and noscan (uint8)
needzero uint8 // needs to be zeroed before allocation
elemsize uintptr // computed from sizeclass or from npages
limit uintptr // end of data in span
state mSpanStateBox // mSpanInUse etc; accessed atomically (get/set methods)
nelems uintptr // number of object in the span.
allocCache uint64
allocCount uint16 // number of allocated objects
...
}mspan与mspan之间以双向链表的形式通过next和prev进行链接,内存地址并不连续。每一个msapn管理着mspan.npages个runtime.pageSize大小的页内存,通常来说页的大小就是 8KB,并且由mspan.startAddr记录着这些页的起始地址和mspan.limit记录着已使用内存的末端地址。每一个mspan所存放的元素大小elemsize是固定的,所以能容纳的元素数量也是固定的。由于数量固定,对象存放就像是数组一样分布在mspan中,范围为[0, nelems],同时由freeindex记录着下一个可用于存放对象的索引。mspan总共有三种状态
- mSpanDead,内存已经被释放
- mSpanInUse,被分配到了堆上
- mSpanManual,被分配到了用于手动管理内存的部分,比如说栈。
决定着mspan元素大小的是spanClass,spanClass自身是一个uint8类型的整数,高七位存放着表示0-67的 class 值,最后一位用于表示noscan即是否包含指针。
type spanClass uint8
func (sc spanClass) sizeclass() int8 {
return int8(sc >> 1)
}
func (sc spanClass) noscan() bool {
return sc&1 != 0
}它总共有 68 种不同的值,所有值都以打表的形式存放于runtime.sizeclasses.go文件中,在运行时,使用spanClass通过runtime.class_to_size可获得mspan的对象大小,通过class_to_allocnpages可获得mspan的页数。
| class | 最大对象大小 | span 大小 | 对象数量 | 尾部浪费 | 最大内存浪费率 | 最小对齐 |
|---|---|---|---|---|---|---|
| 1 | 8 | 8192 | 1024 | 0 | 87.50% | 8 |
| 2 | 16 | 8192 | 512 | 0 | 43.75% | 16 |
| 3 | 24 | 8192 | 341 | 8 | 29.24% | 8 |
| 4 | 32 | 8192 | 256 | 0 | 21.88% | 32 |
| 5 | 48 | 8192 | 170 | 32 | 31.52% | 16 |
| 6 | 64 | 8192 | 128 | 0 | 23.44% | 64 |
| 7 | 80 | 8192 | 102 | 32 | 19.07% | 16 |
| 8 | 96 | 8192 | 85 | 32 | 15.95% | 32 |
| 9 | 112 | 8192 | 73 | 16 | 13.56% | 16 |
| 10 | 128 | 8192 | 64 | 0 | 11.72% | 128 |
| 11 | 144 | 8192 | 56 | 128 | 11.82% | 16 |
| 12 | 160 | 8192 | 51 | 32 | 9.73% | 32 |
| 13 | 176 | 8192 | 46 | 96 | 9.59% | 16 |
| 14 | 192 | 8192 | 42 | 128 | 9.25% | 64 |
| 15 | 208 | 8192 | 39 | 80 | 8.12% | 16 |
| 16 | 224 | 8192 | 36 | 128 | 8.15% | 32 |
| 17 | 240 | 8192 | 34 | 32 | 6.62% | 16 |
| 18 | 256 | 8192 | 32 | 0 | 5.86% | 256 |
| 19 | 288 | 8192 | 28 | 128 | 12.16% | 32 |
| 20 | 320 | 8192 | 25 | 192 | 11.80% | 64 |
| 21 | 352 | 8192 | 23 | 96 | 9.88% | 32 |
| 22 | 384 | 8192 | 21 | 128 | 9.51% | 128 |
| 23 | 416 | 8192 | 19 | 288 | 10.71% | 32 |
| 24 | 448 | 8192 | 18 | 128 | 8.37% | 64 |
| 25 | 480 | 8192 | 17 | 32 | 6.82% | 32 |
| 26 | 512 | 8192 | 16 | 0 | 6.05% | 512 |
| 27 | 576 | 8192 | 14 | 128 | 12.33% | 64 |
| 28 | 640 | 8192 | 12 | 512 | 15.48% | 128 |
| 29 | 704 | 8192 | 11 | 448 | 13.93% | 64 |
| 30 | 768 | 8192 | 10 | 512 | 13.94% | 256 |
| 31 | 896 | 8192 | 9 | 128 | 15.52% | 128 |
| 32 | 1024 | 8192 | 8 | 0 | 12.40% | 1024 |
| 33 | 1152 | 8192 | 7 | 128 | 12.41% | 128 |
| 34 | 1280 | 8192 | 6 | 512 | 15.55% | 256 |
| 35 | 1408 | 16384 | 11 | 896 | 14.00% | 128 |
| 36 | 1536 | 8192 | 5 | 512 | 14.00% | 512 |
| 37 | 1792 | 16384 | 9 | 256 | 15.57% | 256 |
| 38 | 2048 | 8192 | 4 | 0 | 12.45% | 2048 |
| 39 | 2304 | 16384 | 7 | 256 | 12.46% | 256 |
| 40 | 2688 | 8192 | 3 | 128 | 15.59% | 128 |
| 41 | 3072 | 24576 | 8 | 0 | 12.47% | 1024 |
| 42 | 3200 | 16384 | 5 | 384 | 6.22% | 128 |
| 43 | 3456 | 24576 | 7 | 384 | 8.83% | 128 |
| 44 | 4096 | 8192 | 2 | 0 | 15.60% | 4096 |
| 45 | 4864 | 24576 | 5 | 256 | 16.65% | 256 |
| 46 | 5376 | 16384 | 3 | 256 | 10.92% | 256 |
| 47 | 6144 | 24576 | 4 | 0 | 12.48% | 2048 |
| 48 | 6528 | 32768 | 5 | 128 | 6.23% | 128 |
| 49 | 6784 | 40960 | 6 | 256 | 4.36% | 128 |
| 50 | 6912 | 49152 | 7 | 768 | 3.37% | 256 |
| 51 | 8192 | 8192 | 1 | 0 | 15.61% | 8192 |
| 52 | 9472 | 57344 | 6 | 512 | 14.28% | 256 |
| 53 | 9728 | 49152 | 5 | 512 | 3.64% | 512 |
| 54 | 10240 | 40960 | 4 | 0 | 4.99% | 2048 |
| 55 | 10880 | 32768 | 3 | 128 | 6.24% | 128 |
| 56 | 12288 | 24576 | 2 | 0 | 11.45% | 4096 |
| 57 | 13568 | 40960 | 3 | 256 | 9.99% | 256 |
| 58 | 14336 | 57344 | 4 | 0 | 5.35% | 2048 |
| 59 | 16384 | 16384 | 1 | 0 | 12.49% | 8192 |
| 60 | 18432 | 73728 | 4 | 0 | 11.11% | 2048 |
| 61 | 19072 | 57344 | 3 | 128 | 3.57% | 128 |
| 62 | 20480 | 40960 | 2 | 0 | 6.87% | 4096 |
| 63 | 21760 | 65536 | 3 | 256 | 6.25% | 256 |
| 64 | 24576 | 24576 | 1 | 0 | 11.45% | 8192 |
| 65 | 27264 | 81920 | 3 | 128 | 10.00% | 128 |
| 66 | 28672 | 57344 | 2 | 0 | 4.91% | 4096 |
| 67 | 32768 | 32768 | 1 | 0 | 12.50% | 8192 |
关于这些值的计算逻辑可以在runtime.mksizeclasses.go的printComment函数中找到,其中的最大内存浪费率的计算公式为
float64((size-prevSize-1)*objects+tailWaste) / float64(spanSize)例如,当class为 2,其最大内存浪费率为
((16-8-1)*512+0)/8192 = 0.4375当class值为 0 时,就是专用于分配大于 32KB 以上的大对象所使用的spanClass,基本上一个大对象就会占用一个mspan。所以,go 的堆内存实际上是由若干个不同固定大小的mspan组成。
heaparena
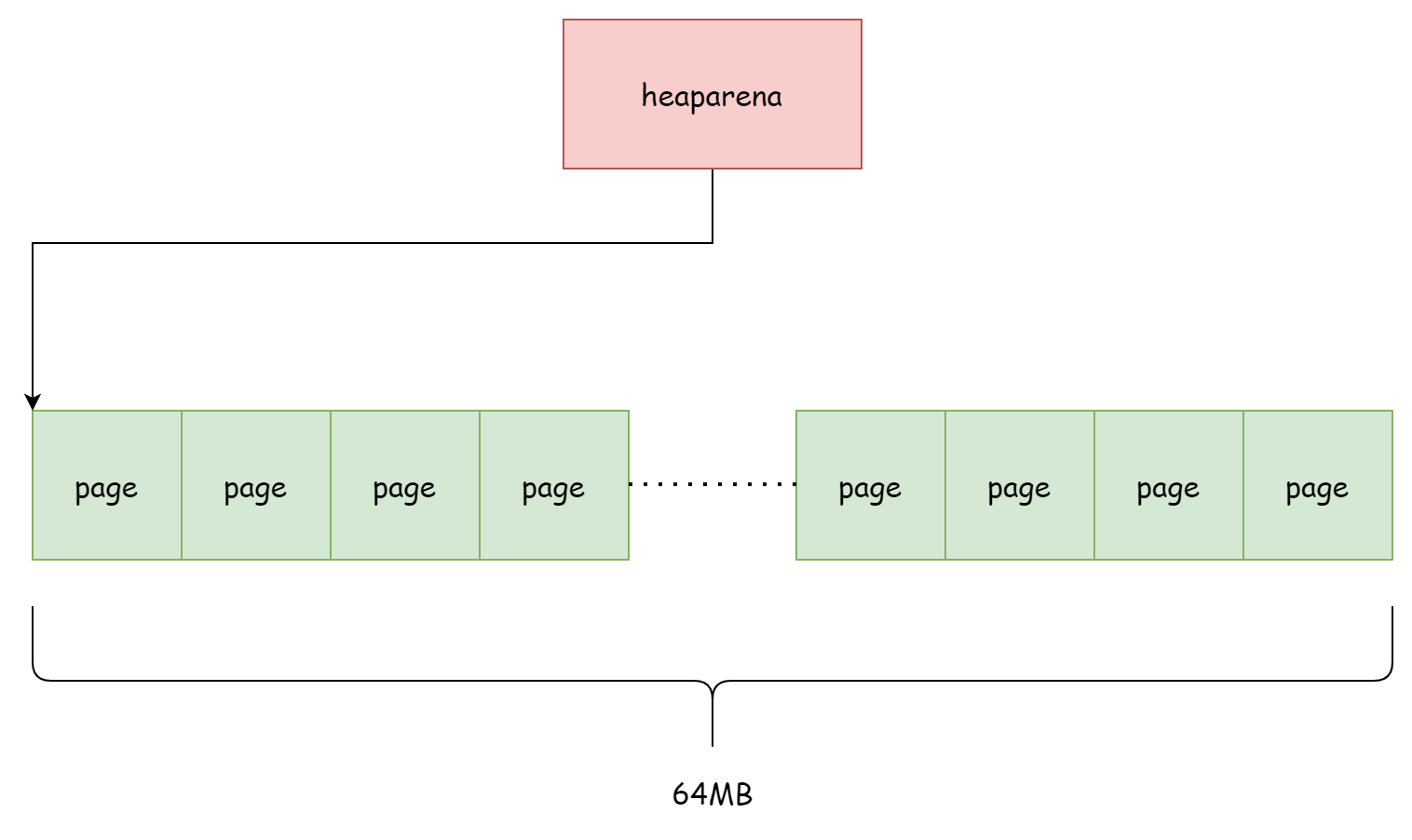
前面提到了mspan是由若干个页组成,但mspan只是持有页的地址引用,并不负责管理这些页,真正负责管理这些页内存的是runtime.heaparena。每一个heaparena管理着若干个页,heaparena的大小由runtime.heapArenaBytes决定,通常是 64MB。bitmap用于标识页中对应的地址是否存放了对象,zeroedBase就是该heaparena所管理的页内存的起始地址,并且由spans记录着每一个页由哪个mspan使用。
type heapArena struct {
_ sys.NotInHeap
bitmap [heapArenaBitmapWords]uintptr
noMorePtrs [heapArenaBitmapWords / 8]uint8
spans [pagesPerArena]*mspan
pageInUse [pagesPerArena / 8]uint8
pageMarks [pagesPerArena / 8]uint8
pageSpecials [pagesPerArena / 8]uint8
checkmarks *checkmarksMap
zeroedBase uintptr
}有关于页与mspan记录的逻辑可以在mheap.setSpans方法中找到,如下所示
func (h *mheap) setSpans(base, npage uintptr, s *mspan) {
p := base / pageSize
ai := arenaIndex(base)
ha := h.arenas[ai.l1()][ai.l2()]
for n := uintptr(0); n < npage; n++ {
i := (p + n) % pagesPerArena
if i == 0 {
ai = arenaIndex(base + n*pageSize)
ha = h.arenas[ai.l1()][ai.l2()]
}
ha.spans[i] = s
}
}在 go 堆中,是由一个二维的heaparena数组来管理所有的页内存,参见mheap.arenas字段。
type mheap struct {
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
}在 64 位 windows 平台上,数组的一维是1 << 6,二维是1 << 16,在 64 位 linux 平台上,一维则是 1,二维就是1 << 22。这个由所有heaparena组成的二维数组就构成了 go 运行时的虚拟内存空间,总体来看就如下图所示。
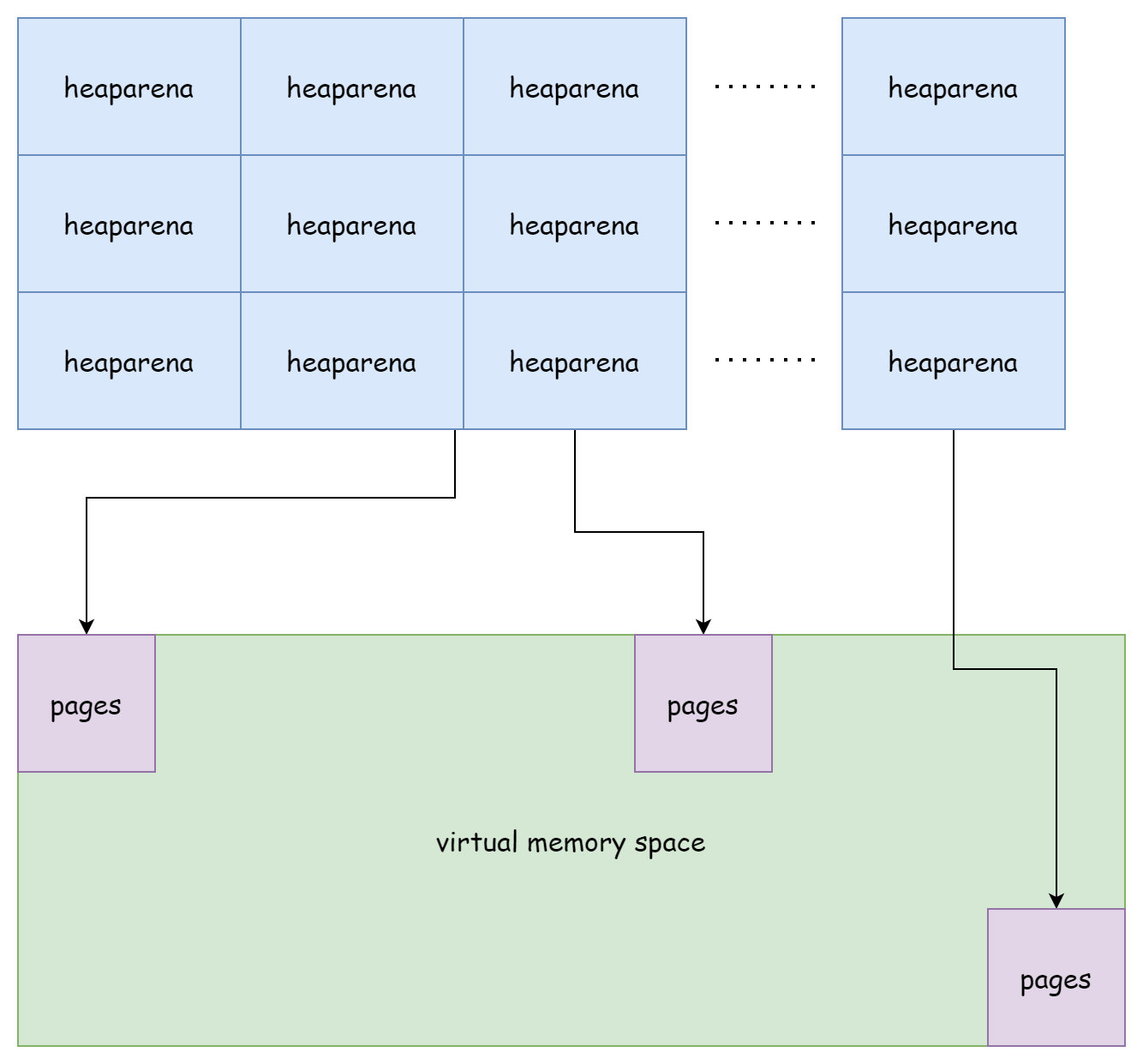
尽管heaparena之间是相邻的,但它们所管理的页内存之间是不连续的。
mcache
mcache对应着runtime.mcache结构体,在并发调度一文中就已经出现过,尽管它的名字叫mcache但它实际上是与处理器 P 绑定的。mcache是每一个处理器 P 上的内存缓存,其中包含了mspan链表数组alloc,数组的大小固定为136,刚好是spanClass数量的两倍,还有微对象缓存tiny,其中tiny指向微对象内存的起始地址,tinyoffset则是空闲内存相对于起始地址的偏移量,tinyAllocs表示分配了多少个微对象。关于栈缓存stackcached,可以前往栈内存分配进行了解。
type mcache struct {
_ sys.NotInHeap
nextSample uintptr // trigger heap sample after allocating this many bytes
scanAlloc uintptr // bytes of scannable heap allocated
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen atomic.Uint32
}在刚初始化时,mcache中的alloc中的链表都只包含一个空的头结点runtime.emptymspan,也就是没有可用内存的mspan。
func allocmcache() *mcache {
var c *mcache
systemstack(func() {
lock(&mheap_.lock)
c = (*mcache)(mheap_.cachealloc.alloc())
c.flushGen.Store(mheap_.sweepgen)
unlock(&mheap_.lock)
})
for i := range c.alloc {
c.alloc[i] = &emptymspan
}
c.nextSample = nextSample()
return c
}仅当在需要进行内存分配时,才会向mcentral申请一个新的mspan来替换原来的空 span,这部分的工作由mcache.refill方法完成,它唯一的调用入口就是runtime.mallocgc函数,下面是简化后的代码。
func (c *mcache) refill(spc spanClass) {
// Return the current cached span to the central lists.
s := c.alloc[spc]
// Get a new cached span from the central lists.
s = mheap_.central[spc].mcentral.cacheSpan()
if s == nil {
throw("out of memory")
}
c.scanAlloc = 0
c.alloc[spc] = s
}使用mcache的好处在于内存分配时不需要全局锁,不过当其内存不足时需要访问mcentral,这时仍然需要加锁。
mcentral
runtime.mcentral管理着堆中所有存放着小对象的mspan,在mcache申请内存时也是由mcentral进行分配。
type mcentral struct {
_ sys.NotInHeap
spanclass spanClass
partial [2]spanSet
full [2]spanSet
}mcentral的字段很少,spanClass表示所存储的mspan类型,partial和full是两个spanSet,前者存放有空闲内存的mspan,后者存放无空闲内存的mspan。mcentral由mheap堆直接进行管理,在运行时总共有 136 个mcentral。
type mheap struct {
central [numSpanClasses]struct {
mcentral mcentral
pad [(cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte
}
}mcentral主要负责两个工作,当内存足够时向mcache分配可用的mspan,当内存不足时向mheap申请分配一个新的mspan。向mcache分配mspan的工作由mcentral.cacheSpan方法来完成。首先会在空闲列表的已清扫集合中寻找可用的mspan。
// Try partial swept spans first.
sg := mheap_.sweepgen
if s = c.partialSwept(sg).pop(); s != nil {
goto havespan
}如果没找到,就在空闲列表的未清扫集合中寻找可用的mspan
for ; spanBudget >= 0; spanBudget-- {
s = c.partialUnswept(sg).pop()
if s == nil {
break
}
if s, ok := sl.tryAcquire(s); ok {
s.sweep(true)
sweep.active.end(sl)
goto havespan
}
}如果仍然没有找到,就到非空闲列表的未清扫集合去寻找
for ; spanBudget >= 0; spanBudget-- {
s = c.fullUnswept(sg).pop()
if s == nil {
break
}
if s, ok := sl.tryAcquire(s); ok {
s.sweep(true)
freeIndex := s.nextFreeIndex()
if freeIndex != s.nelems {
s.freeindex = freeIndex
sweep.active.end(sl)
goto havespan
}
c.fullSwept(sg).push(s.mspan)
}
}如果最终还是没有找到,那么就会由mcentral.grow方法向mheap申请分配一个新的mspan。
s = c.grow()
if s == nil {
return nil
}在正常情况下,无论如何都会返回一个可用的mspan。
havespan:
freeByteBase := s.freeindex &^ (64 - 1)
whichByte := freeByteBase / 8
// Init alloc bits cache.
s.refillAllocCache(whichByte)
s.allocCache >>= s.freeindex % 64
return s对于向mheap申请mspan的过程,实则是调用了mheap.alloc方法,该方法会返回一个新的mspan。
func (c *mcentral) grow() *mspan {
npages := uintptr(class_to_allocnpages[c.spanclass.sizeclass()])
size := uintptr(class_to_size[c.spanclass.sizeclass()])
s := mheap_.alloc(npages, c.spanclass)
if s == nil {
return nil
}
n := s.divideByElemSize(npages << _PageShift)
s.limit = s.base() + size*n
s.initHeapBits(false)
return s
}将其初始化好后就可以分配给mcache使用。
mheap
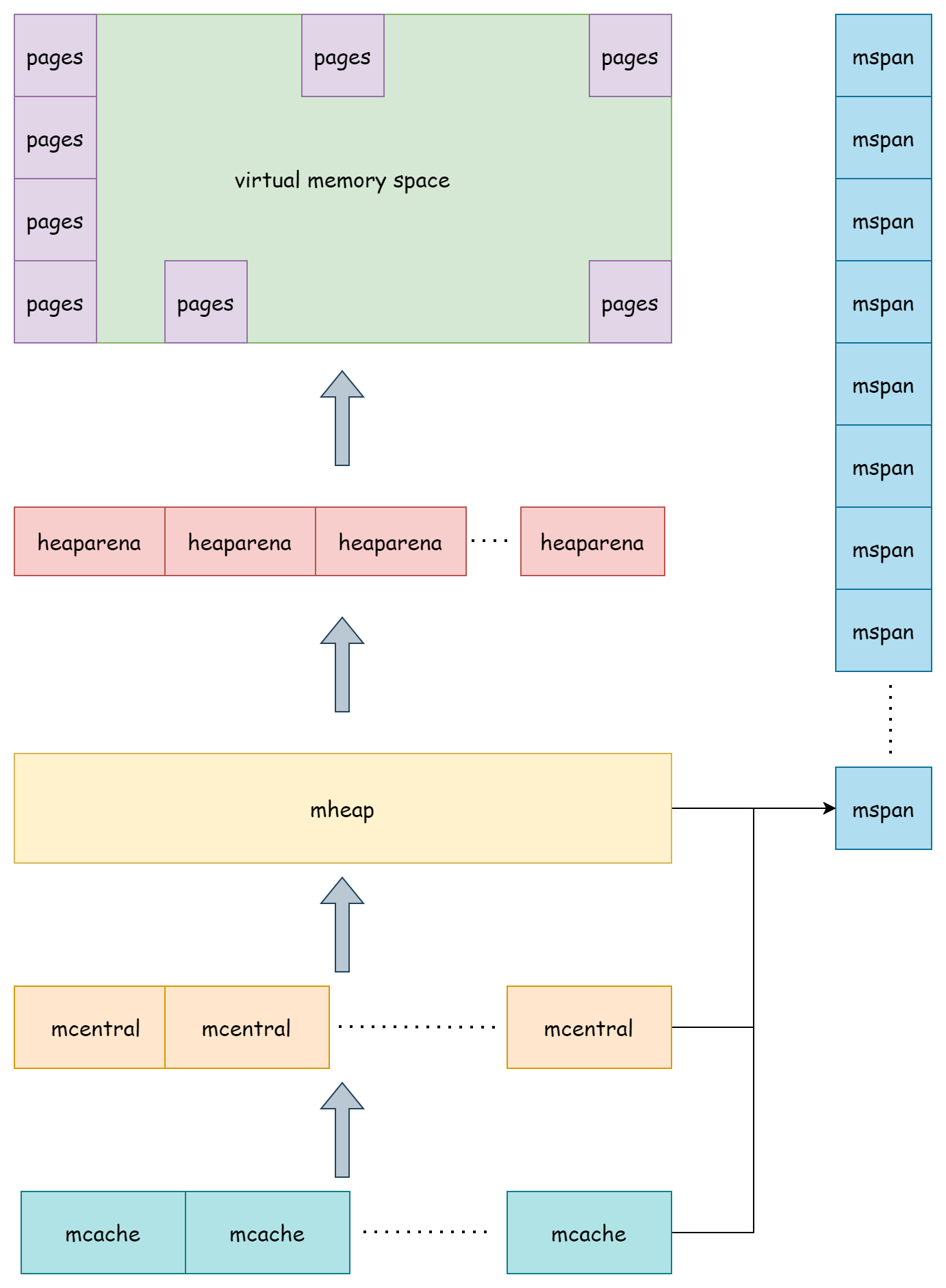
runtimme.mheap是 go 语言堆内存的管理者,在运行时它作为全局变量runtime.mheap_而存在。
var mheap_ mheap它管理着所有被创建的mspan,所有的mcentral,以及所有的heaparena,还有许多其它的各式各样的分配器,其简化后的结构如下所示
type mheap struct {
_ sys.NotInHeap
lock mutex
allspans []*mspan // all spans out there
pagesInUse atomic.Uintptr // pages of spans in stats mSpanInUse
pagesSwept atomic.Uint64 // pages swept this cycle
pagesSweptBasis atomic.Uint64 // pagesSwept to use as the origin of the sweep ratio
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
allArenas []arenaIdx
sweepArenas []arenaIdx
central [numSpanClasses]struct {
mcentral mcentral
pad [(cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize) % cpu.CacheLinePadSize]byte
}
pages pageAlloc // page allocation data structure
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
specialprofilealloc fixalloc // allocator for specialprofile*
specialReachableAlloc fixalloc // allocator for specialReachable
specialPinCounterAlloc fixalloc // allocator for specialPinCounter
arenaHintAlloc fixalloc // allocator for arenaHints
}对于mheap而言,在运行时主要有以下四个工作要做
- 初始化堆
- 分配
mspan - 释放
mspan - 堆扩容
下面按照顺序来讲讲这四件事。
初始化
堆的初始化时期位于程序的引导阶段,同时也是调度器的初始化阶段,其调用顺序为
schedinit() -> mallocinit() -> mheap_.init()在初始化时期,它主要是负责执行各个分配器的初始化工作
func (h *mheap) init() {
h.spanalloc.init(unsafe.Sizeof(mspan{}), recordspan, unsafe.Pointer(h), &memstats.mspan_sys)
h.cachealloc.init(unsafe.Sizeof(mcache{}), nil, nil, &memstats.mcache_sys)
h.specialfinalizeralloc.init(unsafe.Sizeof(specialfinalizer{}), nil, nil, &memstats.other_sys)
h.specialprofilealloc.init(unsafe.Sizeof(specialprofile{}), nil, nil, &memstats.other_sys)
h.specialReachableAlloc.init(unsafe.Sizeof(specialReachable{}), nil, nil, &memstats.other_sys)
h.specialPinCounterAlloc.init(unsafe.Sizeof(specialPinCounter{}), nil, nil, &memstats.other_sys)
h.arenaHintAlloc.init(unsafe.Sizeof(arenaHint{}), nil, nil, &memstats.other_sys)
h.spanalloc.zero = false
for i := range h.central {
h.central[i].mcentral.init(spanClass(i))
}
h.pages.init(&h.lock, &memstats.gcMiscSys, false)
}其中就包括了负责分配mspan的分配器mheap.spanalloc和负责页分配的分配器mheap.pages,以及所有mcentral的初始化。
分配
在mheap中,mspan的分配都由mheap.allocSpan方法来完成
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan)如果申请分配的内存足够小,即满足npages < pageCachePages/4,那么就会尝试不加锁在本地的 P 中的mspan缓存中去获取一个可用的mspan,倘若 P 的缓存是空的话,还会先进行初始化
// If the cache is empty, refill it.
if c.empty() {
lock(&h.lock)
*c = h.pages.allocToCache()
unlock(&h.lock)
}然后再从 P 缓存中获取,由mheap.tryAllocMSpan方法完成。
pp := gp.m.p.ptr()
if !needPhysPageAlign && pp != nil && npages < pageCachePages/4 {
c := &pp.pcache
base, scav = c.alloc(npages)
if base != 0 {
s = h.tryAllocMSpan()
if s != nil {
goto HaveSpan
}
}
}从 P 缓存中获取mspan的代码如下,它会尝试获取缓存中最后一个mspan。
func (h *mheap) tryAllocMSpan() *mspan {
pp := getg().m.p.ptr()
// If we don't have a p or the cache is empty, we can't do
// anything here.
if pp == nil || pp.mspancache.len == 0 {
return nil
}
// Pull off the last entry in the cache.
s := pp.mspancache.buf[pp.mspancache.len-1]
pp.mspancache.len--
return s
}如果申请的内存比较大的话,就会在堆上分配内存,这个过程中需要持有锁
lock(&h.lock)
if base == 0 {
// Try to acquire a base address.
base, scav = h.pages.alloc(npages)
if base == 0 {
var ok bool
growth, ok = h.grow(npages)
if !ok {
unlock(&h.lock)
return nil
}
base, scav = h.pages.alloc(npages)
if base == 0 {
throw("grew heap, but no adequate free space found")
}
}
}
if s == nil {
// We failed to get an mspan earlier, so grab
// one now that we have the heap lock.
s = h.allocMSpanLocked()
}
unlock(&h.lock)首先会使用pageAlloc.alloc来为其分配足够的页内存,如果堆内存不够的会就由mheap.grow来进行扩容。页内存分配完成后,就会由链式分配mheap.spanalloc分配 64 个mspan到 P 本地的缓存中,64 正好是缓存数组长度的一半,然后再从 P 缓存中返回一个可用的mspan。
func (h *mheap) allocMSpanLocked() *mspan {
assertLockHeld(&h.lock)
pp := getg().m.p.ptr()
if pp == nil {
// We don't have a p so just do the normal thing.
return (*mspan)(h.spanalloc.alloc())
}
// Refill the cache if necessary.
if pp.mspancache.len == 0 {
const refillCount = len(pp.mspancache.buf) / 2
for i := 0; i < refillCount; i++ {
pp.mspancache.buf[i] = (*mspan)(h.spanalloc.alloc())
}
pp.mspancache.len = refillCount
}
// Pull off the last entry in the cache.
s := pp.mspancache.buf[pp.mspancache.len-1]
pp.mspancache.len--
return s
}根据上面两种情况,最终都能得到一个可用的mspan,最后将mspan初始化完毕后就可以返回了
HaveSpan:
h.initSpan(s, typ, spanclass, base, npages)
return s释放
既然mspan是由链式分配器的,自然释放内存的时候也由它来进行释放。
func (h *mheap) freeSpanLocked(s *mspan, typ spanAllocType) {
assertLockHeld(&h.lock)
// Mark the space as free.
h.pages.free(s.base(), s.npages)
s.state.set(mSpanDead)
h.freeMSpanLocked(s)
}首先会通过页分配器mheap.pages标记指定的页内存被释放,然后将mspan的状态设置为mSpanDead,最后由mheap.spanalloc分配器释放mspan。
func (h *mheap) freeMSpanLocked(s *mspan) {
assertLockHeld(&h.lock)
pp := getg().m.p.ptr()
// First try to free the mspan directly to the cache.
if pp != nil && pp.mspancache.len < len(pp.mspancache.buf) {
pp.mspancache.buf[pp.mspancache.len] = s
pp.mspancache.len++
return
}
// Failing that (or if we don't have a p), just free it to
// the heap.
h.spanalloc.free(unsafe.Pointer(s))
}如果 P 缓存未满的话,会将其放入 P 本地的缓存中继续使用,否则的话它会被释放回堆内存。
扩容
heaparena所管理的页内存空间并非在初期就已经全部申请好了,只有需要用到内存的时候才会去分配。负责给堆内存扩容的是mheap.grow方法,下面是简化后的代码。
func (h *mheap) grow(npage uintptr) (uintptr, bool) {
assertLockHeld(&h.lock)
ask := alignUp(npage, pallocChunkPages) * pageSize
totalGrowth := uintptr(0)
end := h.curArena.base + ask
nBase := alignUp(end, physPageSize)
if nBase > h.curArena.end || end < h.curArena.base {
av, asize := h.sysAlloc(ask, &h.arenaHints, true)
if uintptr(av) == h.curArena.end {
h.curArena.end = uintptr(av) + asize
} else {
// Switch to the new space.
h.curArena.base = uintptr(av)
h.curArena.end = uintptr(av) + asize
}
nBase = alignUp(h.curArena.base+ask, physPageSize)
}
...
}它首先会根据npage计算所需内存并进行对齐, 然后判断当前heaparena是否有足够的内存,如果不够的话就会由mheap.sysAlloc为当前heaparena申请更多内存或者分配一个新的heaparena。
func (h *mheap) sysAlloc(n uintptr, hintList **arenaHint, register bool) (v unsafe.Pointer, size uintptr) {
n = alignUp(n, heapArenaBytes)
if hintList == &h.arenaHints {
v = h.arena.alloc(n, heapArenaBytes, &gcController.heapReleased)
if v != nil {
size = n
goto mapped
}
}
...
}首先会尝试使用线性分配器mheap.arena在预分配的内存空间中申请一块内存,如果失败就根据hintList来进行扩容,hintList的类型为runtime.arenaHint,它专门记录了用于heaparena扩容相关的地址信息。
for *hintList != nil {
hint := *hintList
p := hint.addr
v = sysReserve(unsafe.Pointer(p), n)
if p == uintptr(v) {
hint.addr = p
size = n
break
}
if v != nil {
sysFreeOS(v, n)
}
*hintList = hint.next
h.arenaHintAlloc.free(unsafe.Pointer(hint))
}内存申请完毕后,再将其更新到arenas二维数组中
for ri := arenaIndex(uintptr(v)); ri <= arenaIndex(uintptr(v)+size-1); ri++ {
l2 := h.arenas[ri.l1()]
var r *heapArena
r = (*heapArena)(h.heapArenaAlloc.alloc(unsafe.Sizeof(*r), goarch.PtrSize, &memstats.gcMiscSys))
atomic.StorepNoWB(unsafe.Pointer(&l2[ri.l2()]), unsafe.Pointer(r))
}最后再由页分配器将这片内存标记为就绪状态。
// Update the page allocator's structures to make this
// space ready for allocation.
h.pages.grow(v, nBase-v)
totalGrowth += nBase - v对象分配
go 在为对象分配内存的时候,根据大小划分为了三个不同的类型:
- 微对象 - tiny,小于 16B
- 小对象 - small,小于 32KB
- 大对象 - large,大于 32KB
根据三种不同的类型,在分配内存的时候会执行不同的逻辑。负责为对象分配内存的函数是runtime.mallocgc,其函数签名如下
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer它只有三个参数,内存大小,类型,以及一个布尔值用于表示是否需要清空内存。它是所有 go 对象内存分配的入口函数,平时在使用new函数创建指针时同样也会走入该函数,当内存分配成功后,它返回的指针就是该对象的地址。在mpan部分中提到过,每一个mspan都拥有一个spanClass,spanClass决定了mspan的固定大小,并且 go 将对象从[0, 32KB]的范围分成了 68 种不同的大小,所以 go 内存由若干个不同的大小固定的mspan链表组成。在分配对象内存时,只需按照对象大小计算出对应的spanClass,然后再根据spanClass找到对应的mspan链表,最后再从链表中寻找可用的mspan,这种分级的做法能较为有效的解决内存碎片的问题。
微对象
所有小于 16B 的非指针微对象会由 P 中的微分配器被分配到同一片连续内存中,在runitme.mcache,由tiny字段记录了这片内存的基地址。
type mcache struct {
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
}微对象的大小由runtime.maxTinySize常量来决定,都是 16B,用于存储微对象的内存块同样也是这个大小,一般来说这里存储的对象都是一些小字符串,负责分配微对象的部分代码如下所示。
if size <= maxSmallSize {
if noscan && size < maxTinySize {
off := c.tinyoffset
if off+size <= maxTinySize && c.tiny != 0 {
x = unsafe.Pointer(c.tiny + off)
c.tinyoffset = off + size
c.tinyAllocs++
mp.mallocing = 0
releasem(mp)
return x
}
// Allocate a new maxTinySize block.
span = c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(tinySpanClass)
}
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
if (size < c.tinyoffset || c.tiny == 0) {
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize如果当前的微内存块还有足够的空间来容纳,就直接使用当前内存块,即off+size <= maxTinySize。如果不够的话,就会先尝试从mcache的 span 缓存中寻找可用的空间,如果也不行的话就会向mcentral申请一个mspan,不管如何最终都会得到一个可用的地址,最后再用新的微对象内存块替换掉旧的。
小对象
go 语言运行时大部分对象都是位于[16B, 32KB]这个范围内的小对象,小对象的分配过程最麻烦,但代码却是最少,负责小对象分配的部分代码如下。
var sizeclass uint8
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)]
} else {
sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]
}
size = uintptr(class_to_size[sizeclass])
spc := makeSpanClass(sizeclass, noscan)
span = c.alloc[spc]
v := nextFreeFast(span)
if v == 0 {
v, span, shouldhelpgc = c.nextFree(spc)
}
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
memclrNoHeapPointers(x, size)
}首先会根据对象的大小计算出应该使用哪一类的spanClass,然后由runtime.nextFreeFast根据spanClass尝试去mcache中对应的缓存mspan获取可用的内存空间。
func nextFreeFast(s *mspan) gclinkptr {
theBit := sys.TrailingZeros64(s.allocCache) // Is there a free object in the allocCache?
if theBit < 64 {
result := s.freeindex + uintptr(theBit)
if result < s.nelems {
freeidx := result + 1
if freeidx%64 == 0 && freeidx != s.nelems {
return 0
}
s.allocCache >>= uint(theBit + 1)
s.freeindex = freeidx
s.allocCount++
return gclinkptr(result*s.elemsize + s.base())
}
}
return 0
}mspan.allocCache的作用是记录内存空间是否有对象使用,并且它是按照对象数量来将内存一个个划分而非按照空间大小来划分,这相当于是把mspan看了一个对象数组,如下图所示。
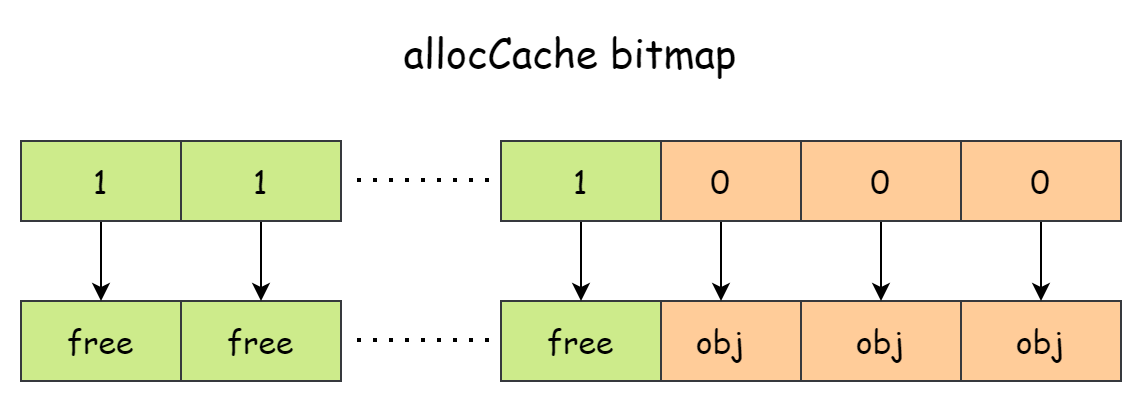
allocCache是一个 64 位数字,每一位对应着一片内存空间,如果某一位为 0 表示有对象使用,如果是 1 的话表示这片内存是空闲的。sys.TrailingZeros64(s.allocCache)的目的就是计算尾随零的数量,如果结果是 64 的话则表明没有空闲的内存可以使用,如果有的话再计算得到空闲内存的偏移量加上mspan的基地址然后返回。
当mcache中没有足够的空间时,就会再去mcentral中去申请,这部分工作由mcache.nextFree方法来完成
func (c *mcache) nextFree(spc spanClass) (v gclinkptr, s *mspan, shouldhelpgc bool) {
s = c.alloc[spc]
shouldhelpgc = false
freeIndex := s.nextFreeIndex()
if freeIndex == s.nelems {
c.refill(spc)
shouldhelpgc = true
s = c.alloc[spc]
freeIndex = s.nextFreeIndex()
}
v = gclinkptr(freeIndex*s.elemsize + s.base())
s.allocCount++
return
}其中的mcache.refill会负责向mcentral申请一个可用的mspan。
func (c *mcache) refill(spc spanClass) {
...
s = mheap_.central[spc].mcentral.cacheSpan()
...
}而mcentral.cacheSpan方法会在内存不足时由mcentral.grow来进行扩容,扩容则又会向mheap去申请新的mspan。
func (c *mcentral) grow() *mspan {
...
s := mheap_.alloc(npages, c.spanclass)
...
return s
}所以最后看来,小对象的内存分配是一级一级往下走的,先是mcache,然后是mcentral,最后是mheap。mcache分配的成本最低,因为它是 P 本地的缓存,分配内存时不需要持有锁,mcentral其次,直接向mheap申请内存成本最高,因为mheap.alloc方法会竞争整个堆的全局锁。
大对象
大对象分配最为简单,如果对象的大小超过了 32KB,就会直接向mheap申请分配一个新的mspan来容纳,负责分配大对象的部分代码如下。
shouldhelpgc = true
span = c.allocLarge(size, noscan)
span.freeindex = 1
span.allocCount = 1
size = span.elemsize
x = unsafe.Pointer(span.base())
if needzero && span.needzero != 0 {
if noscan {
delayedZeroing = true
} else {
memclrNoHeapPointers(x, size)
}
}其中mcache.allocLarge负责向mheap申请大对象的内存空间
func (c *mcache) allocLarge(size uintptr, noscan bool) *mspan {
...
spc := makeSpanClass(0, noscan)
s := mheap_.alloc(npages, spc)
...
return s
}从代码中可以看到的是大对象使用的spanClass值为 0,大对象基本上都是一个对象占用一个mpan。
其它
内存统计
go 运行时对用户暴露了一个函数ReadMemStats,可以用于统计运行时的内存情况。
func ReadMemStats(m *MemStats) {
_ = m.Alloc // nil check test before we switch stacks, see issue 61158
stopTheWorld(stwReadMemStats)
systemstack(func() {
readmemstats_m(m)
})
startTheWorld()
}但是使用它的代价非常大,从代码中可以看到分析内存情况前需要 STW,而 STW 的时长可能是几毫秒到几百毫秒不等,一般只有在调试和问题排查的时候才会使用。runtime.MemStats结构体记录了有关堆内存,栈内存,和 GC 相关的信息
type MemStats struct {
// 总体统计
Alloc uint64
TotalAlloc uint64
Sys uint64
Lookups uint64
Mallocs uint64
Frees uint64
// 堆内存统计
HeapAlloc uint64
HeapSys uint64
HeapIdle uint64
HeapInuse uint64
HeapReleased uint64
HeapObjects uint64
// 栈内存统计
StackInuse uint64
StackSys uint64
// 内存组件统计
MSpanInuse uint64
MSpanSys uint64
MCacheInuse uint64
MCacheSys uint64
BuckHashSys uint64
// gc相关的统计
GCSys uint64
OtherSys uint64
NextGC uint64
LastGC uint64
PauseTotalNs uint64
PauseNs [256]uint64
PauseEnd [256]uint64
NumGC uint32
NumForcedGC uint32
GCCPUFraction float64
EnableGC bool
DebugGC bool
BySize [61]struct {
Size uint32
Mallocs uint64
Frees uint64
}
}NotInHeap
内存分配器显然用来分配堆内存的,但堆又被分为了两部分,一部分是 go 运行时自身所需要的堆内存,另一部分是开放给用户使用的堆内存。所以在一些结构中可以看到这样的嵌入字段
_ sys.NotInHeap表示该类型的内存不会分配在用户堆上,这种嵌入字段在内存分配组件中尤为常见,比如表示用户堆的结构体runtime.mheap
type mheap struct {
_ sys.NotInHeap
}sys.NotInHeap的真正作用是为了避免内存屏障以提高运行时效率,而用户堆需要运行 GC 所以需要内存屏障。