defer
defer
defer在 go 的日常开发中是一个出现频率非常高的关键字,它会以先进后出的方式来执行defer关联的函数,很多时候我们利用这种机制来进行一些资源的释放操作,比如文件关闭之类的操作。
fd, err := os.Open("/dev/stdin")
if err != nil{
return err
}
defer fd.Close()
...如此高频出现的关键字,使得我们有必要去了解一下它背后的结构。
结构
defer关键字对应runtime._defer结构体,它的结构并不复杂
type _defer struct {
started bool
heap bool
openDefer bool
sp uintptr // sp at time of defer
pc uintptr // pc at time of defer
fn func() // can be nil for open-coded defers
_panic *_panic // panic that is running defer
link *_defer // next defer on G; can point to either heap or stack!
fd unsafe.Pointer // funcdata for the function associated with the frame
varp uintptr // value of varp for the stack frame
framepc uintptr
}其中的fn字段是defer关键字对应的函数,link表示下一个链接的defer,sp和pc记录了调用方的函数信息,用于判断defer属于哪一个函数。defer 在运行时以链表的形式存在,链表的头部就在协程 G 上,所以defer实际上是与协程直接关联的。
type g struct {
...
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
...
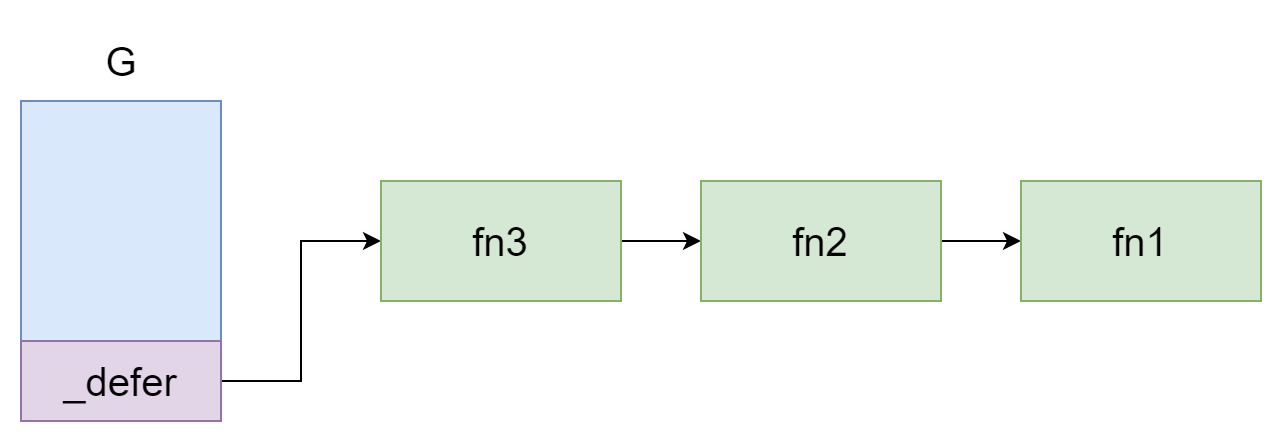
}当协程执行函数时,就会按照顺序将函数中的defer从链表的头部加入
defer fn1()
defer fn2()
defer fn3()上面那段代码就对应这幅图
除了协程之外,P 也跟defer有一定的关联,在 P 的结构体中,有一个deferpool字段,如所示。
type p struct {
...
deferpool []*_defer // pool of available defer structs (see panic.go)
deferpoolbuf [32]*_defer
...
}deferpool中存放着预分配好的defer结构,用于给与 P 关联的协程 G 分配新的defer结构,可以减少开销。
分配
在语法上对defer关键字的使用,编译器会将其转为为对runtime.deferproc函数的调用。比如 go 代码是这样写的
defer fn1(x, y)而编译后实际上的代码是这样的
deferproc(func(){
fn1(x, y)
})所以实际上defer传入的函数是没有参数也没有返回值的,deferproc函数代码如下所示
func deferproc(fn func()) {
gp := getg()
d := newdefer()
d.link = gp._defer
gp._defer = d
d.fn = fn
d.pc = getcallerpc()
d.sp = getcallersp()
return0()
}该函数负责创建defer结构并将其加入协程 G 链表的头部,其中的runtime.newdefer函数就会尝试从 P 中的deferpool来获取预分配的defer结构。
if len(pp.deferpool) == 0 && sched.deferpool != nil {
lock(&sched.deferlock)
for len(pp.deferpool) < cap(pp.deferpool)/2 && sched.deferpool != nil {
d := sched.deferpool
sched.deferpool = d.link
d.link = nil
pp.deferpool = append(pp.deferpool, d)
}
unlock(&sched.deferlock)
}它首先会从全局的sched.deferpool向局部的deferpool装填一半的defer结构,然后再从 P 中的deferpool尝试去获取
if n := len(pp.deferpool); n > 0 {
d = pp.deferpool[n-1]
pp.deferpool[n-1] = nil
pp.deferpool = pp.deferpool[:n-1]
}
if d == nil {
// Allocate new defer.
d = new(_defer)
}
d.heap = true最后实在找不到才会使用手动分配的方式。最后可以看到有这么一段代码
d.heap = true这表示defer在堆上分配,相应的当其为false时,就会在栈上分配,栈上分配的内存会在返回时自动回收,其内存管理效率要比在堆上更高,而决定是否在栈上分配的因素就是循环层数,这部分逻辑可以追溯到cmd/compile/ssagen中的escape.goDeferStmt方法的这一小段,如下所示
func (e *escape) goDeferStmt(n *ir.GoDeferStmt) {
...
if n.Op() == ir.ODEFER && e.loopDepth == 1 {
k = e.later(e.discardHole())
n.SetEsc(ir.EscNever)
}
...
}e.loopDepth表示的就是当前语句的循环层数,如果当前defer语句不在循环中,就会将其分配到栈上。
case ir.ODEFER:
n := n.(*ir.GoDeferStmt)
if s.hasOpenDefers {
s.openDeferRecord(n.Call.(*ir.CallExpr))
} else {
d := callDefer
if n.Esc() == ir.EscNever {
d = callDeferStack
}
s.callResult(n.Call.(*ir.CallExpr), d)
}如果是在栈上分配的话,就会直接在栈上创建defer结构体,最终会由runtime.deferprocStack函数来完成defer结构的创建。
if k == callDeferStack {
// Make a defer struct d on the stack.
if stksize != 0 {
s.Fatalf("deferprocStack with non-zero stack size %d: %v", stksize, n)
}
t := deferstruct()
...
// Call runtime.deferprocStack with pointer to _defer record.
ACArgs = append(ACArgs, types.Types[types.TUINTPTR])
aux := ssa.StaticAuxCall(ir.Syms.DeferprocStack, s.f.ABIDefault.ABIAnalyzeTypes(nil, ACArgs, ACResults))
callArgs = append(callArgs, addr, s.mem())
call = s.newValue0A(ssa.OpStaticLECall, aux.LateExpansionResultType(), aux)
call.AddArgs(callArgs...)
call.AuxInt = int64(types.PtrSize) // deferprocStack takes a *_defer argdeferprocStack函数的签名如下
func deferprocStack(d *_defer)其具体的创建逻辑与deferproc并无太大区别,主要的区别在于,在栈上分配时是defer结构的来源是直接创建的结构体,在堆上分配的defer来源是new函数。
执行
当函数将要返回或者发生panic时,便会进入runtime.deferreturn函数,它负责从协程的链表中取出defer并执行。
func deferreturn() {
gp := getg()
for {
d := gp._defer
sp := getcallersp()
if d.sp != sp {
return
}
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
fn()
}
}首先会通过getcallersp()获取当前函数的栈帧并与defer结构中的sp做比较来判断defer是否属于当前函数,然后将defer结构从链表头部取出,并使用gp._defer = d.link执行下一个defer,再通过runtuime.freedefer函数将defer结构释放回池中,最后再调用fn执行,就这样一直循环到执行完属于当前函数的所有defer结束为止。
开放编码
defer的使用并非毫无成本,虽然它在语法上给我们提供了便利,但毕竟它不是直接进行函数调用,中间会进行经过一系列的过程,所以还是会造成性能损耗,所以后来 go 官方设计了一种优化方——开放编码,它是一种对defer的优化方式,其原英文名叫 open-coded,国内基本上都给翻译成了开放编码,这里的 open 指的是展开的意思,就是将defer函数的代码展开到当前函数代码中,就像函数内联一样。这种优化方式有以下几个限制条件
- 函数中的
defer数量不能超过 8 个 defer与return两者数量的乘积不能超过 15defer不能出现在循环中- 未禁用编译优化
- 没有手动调用
os.Exit() - 不需要从堆上复制参数
这部分判断逻辑可以追溯到cmd/compile/ssagen.buildssa函数的下面这部分代码
s.hasOpenDefers = base.Flag.N == 0 && s.hasdefer && !s.curfn.OpenCodedDeferDisallowed()
if s.hasOpenDefers && len(s.curfn.Exit) > 0 {
s.hasOpenDefers = false
}
if s.hasOpenDefers {
for _, f := range s.curfn.Type().Results().FieldSlice() {
if !f.Nname.(*ir.Name).OnStack() {
s.hasOpenDefers = false
break
}
}
}
if s.hasOpenDefers && s.curfn.NumReturns*s.curfn.NumDefers > 15 {
s.hasOpenDefers = false
}然后 go 会在当前函数创建一个 8 位整数变量deferBits来当作 bitmap 用于标记defer,每一位标记一个,8 位整数uint8最多表示 8 个,如果对应位为 1,那么对应的开放编码优化后的defer就会在函数要返回时执行。