slice
slice
提示
阅读本文需要unsafe标准库的知识。
切片应该是 go 语言中最最常用的数据结构,没有之一(实际上内置的数据结构也没几个),几乎在任何地方都能看到它的身影。关于它的基本用法在语言入门中已经阐述过了,下面来看看它的内部长什么样,以及它内部是如何运作的。
结构
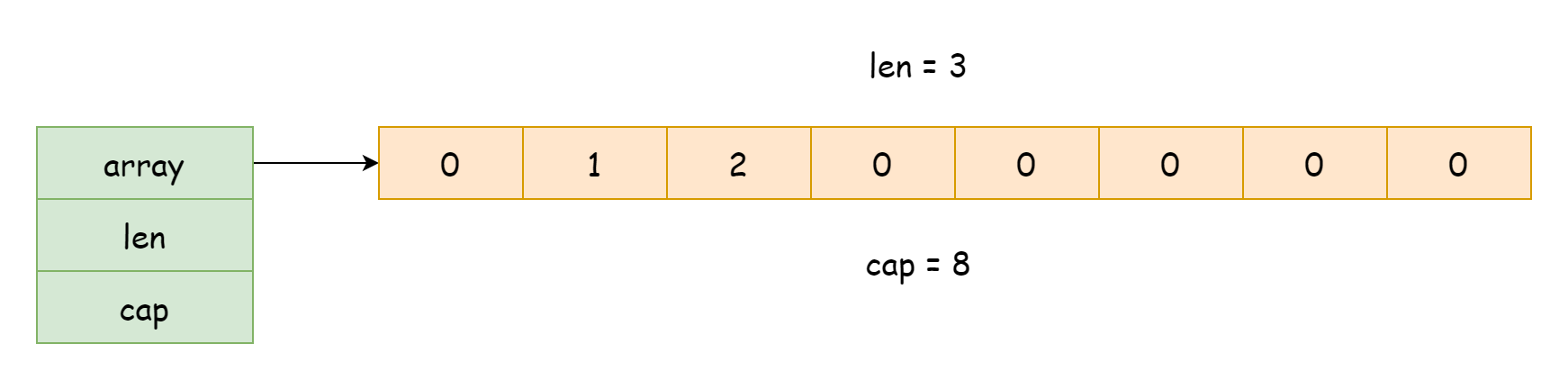
有关切片的实现,其源代码位于runtime/slice.go文件中。在运行时,切片以一个结构体的形式而存在,其类型为runtime.slice,如下所示。
type slice struct {
array unsafe.Pointer
len int
cap int
}这个结构体只有三个字段
array,指向底层数组的指针len,切片的长度,指的是数组中已有的元素数量cap,切片的容量,指的是数组能容纳元素的总数
从上面的信息可以得知,切片的底层实现还是依赖于数组,在平时它只是一个结构体,只持有对数组的引用,以及容量和长度的记录。这样一来传递切片的成本就会非常低,只需要复制其数据的引用,并不用复制所有数据,并且在使用len和cap获取切片的长度和容量时,就等于是在获取其字段值,不需要去遍历数组。
不过这同样也会带来一些不容易发现的问题,看下面的一个例子
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1[0] = 2
fmt.Println(s)
}[2 2 3 4 5]在上面的代码中,s1通过切割的方式创建了一个新的切片,但它和源切片所引用的都是同一个底层数组,修改s1中的数据也会导致s发生变化。所以复制切片的时候应该使用copy函数,后者复制的切片与前者毫不相干。再来看个例子
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
s1 := s[:]
s1 = append(s1, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
s1[0] = 10
fmt.Println(s)
fmt.Println(s1)
}[1 2 3 4 5]
[10 2 3 4 5 1 2 3 4 5 6 7 8 9 10]同样是使用切割方式复制切片,但这一次不会对源切片造成影响。最初s1和s确实指向的同一个数组,但是后续对s1添加了过多的元素超过了数组所能容纳的数量,于是便分配了一个更大的新数组来盛放元素,所以最后它们两个指向的就是不同的数组了。是不是觉得已经没问题了,那就再来看一个例子
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
appendData(s, 1, 2, 3, 4, 5, 6)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]明明已经添加了元素,但是打印出来的确是空切片,实际上数据确实是已经添加到了切片中,只不过是写入到了底层数组。go 中的函数参数是传值传递,所以参数s实际上源切片结构体的一个拷贝,而append操作在添加元素后会返回一个更新了长度的切片结构体,只不过赋值的是参数s而非源切片s,两者并其实没有什么联系。
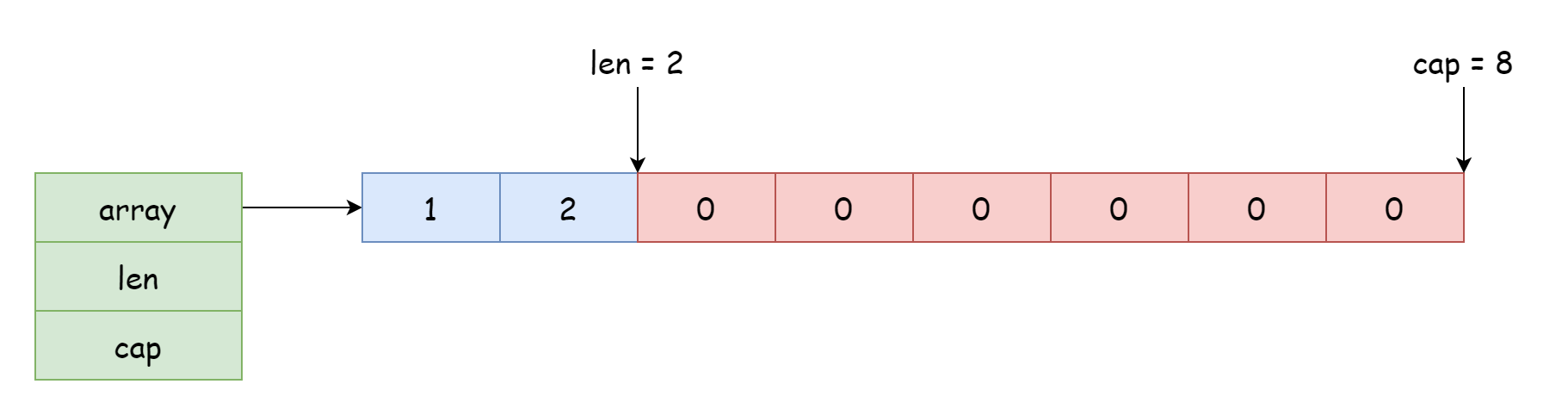
对于一个切片而言,它能访问和修改的起始位置取决于对数组的引用位置,偏移量取决于结构体中记录的长度。结构体中的指针除了可以指向开头,也可以数组的中间,就像下面这张图一样。
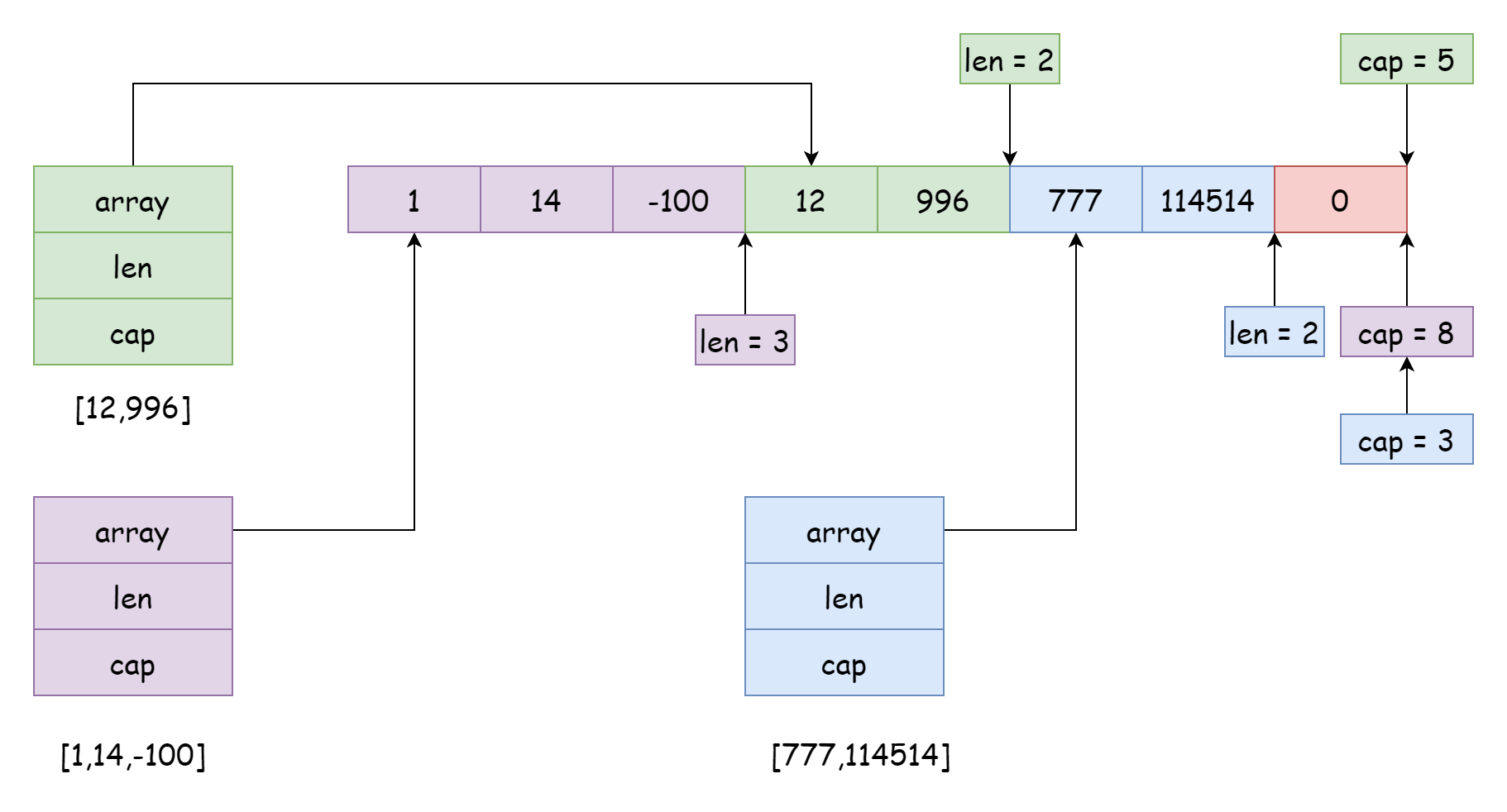
一个底层数组可以被很多个切片所引用,且引用的位置和范围可以不同,就像上图一样,这种情况一般出现在对切片进行切割的时候,类似下面的代码
s := make([]int, 0, 10)
s1 := s[:4]
s2 := s[4:6]
s3 := s[7:]在切割时,生成的新切片的容量等于数组长度减去新切片引用的起始位置。例如s[4:6]生成的新切片容量就是6 = 10 - 4。当然,切片引用的范围也不一定非得相邻,也可以相互交错,不过这会产生非常大的麻烦,可能当前切片的数据在不知情的情况下就被别的切片修改了,比如上图中的紫色切片,如果在后续过程中使用append添加元素,就有可能会把绿色切片和蓝色切片的数据覆盖。为了避免这种情况,go 允许在切割时设置容量范围,语法如下。
s4 = s[4:6:6]在这种情况下,它的容量就被限制到了 2,那么添加元素就会触发扩容,扩容后就是一个新数组了,与源数组就没有关系了,就不会有影响。你以为关于切片的问题到这里就结束了吗,其实并没有,再来看一个例子。
package main
import "fmt"
func main() {
s := make([]int, 0, 10)
// 添加的元素数量刚好大于容量
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println(s)
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
}[]代码跟上一个例子没有区别,只是修改了一下入参,让添加的元素数量刚好大于切片的容量,这样在添加时就会触发扩容,这样一来,数据不仅没有添加到源切片s,甚至连其指向的底层数组也没有被写入数据,我们可以通过unsafe指针来证实一下,代码如下
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 0, 10)
// 添加的元素数量刚好大于容量
appendData(s, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)
fmt.Println("ori slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func appendData[T comparable](s []T, data ...T) {
s = append(s, data...)
fmt.Println("new slice", unsafe.SliceData(s))
unsafeIterator(unsafe.Pointer(unsafe.SliceData(s)), cap(s))
}
func unsafeIterator(ptr unsafe.Pointer, offset int) {
for ptr, i := ptr, 0; i < offset; ptr, i = unsafe.Add(ptr, unsafe.Sizeof(int(0))), i+1 {
elem := *(*int)(ptr)
fmt.Printf("%d, ", elem)
}
fmt.Println()
}new slice 0xc0000200a0
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 0, 0, 0, 0, 0, 0, 0, 0, 0,
ori slice 0xc000018190
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,可以看到的是,源切片的底层数组空空如也,一点东西也没有,数据全都被写入新数组中了,不过跟源切片没什么关系,因为即便append返回了新的引用,修改的也只是形参s的值,影响不到源切片s。切片作为结构体确实可以让其非常轻量,但是上面的问题同样不可忽视,尤其是在实际的代码中这些问题通常藏的很深,很难被发现。
创建
在运行时,使用make函数创建切片的工作由runtime.makeslice,来完成,它的逻辑比较简单,该函数签名如下
func makeslice(et *_type, len, cap int) unsafe.Pointer它接收三个参数,元素类型,长度,容量,完成后返回一个指向底层数组的指针,它的代码如下
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 计算需要的总内存,如果太大会导致数值溢出
// mem = sizeof(et) * cap
mem, overflow := math.MulUintptr(et.Size_, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// mem = sizeof(et) * len
mem, overflow := math.MulUintptr(et.Size_, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 没问题的话就分配内存
return mallocgc(mem, et, true)
}可以看到逻辑非常简单,总共就做了两件事
- 计算所需内存
- 分配内存空间
如果条件检查失败了,就会直接panic
- 内存计算时数值溢出了
- 计算结果大于可分配的最大内存
- 长度与容量不合法
如果计算得到内存大于32KB,就会将其分配到堆上,完事之后就会返回一个指向底层数组的指针,构建runtime.slice结构体的工作并不由makeslice函数来完成。实际上,构建结构体的工作是编译期间完成的,运行时的makeslice函数只负责分配内存,类似如下的代码。
var s runtime.slice
s.array = runtime.makeslice(type,len,cap)
s.len = len
s.cap = cap感兴趣的话可以去看看生成的中间代码,跟这个类似。
name s.ptr[*int]: v11
name s.len[int]: v7
name s.cap[int]: v8如果是使用数组来创建切片的话,比如下面这种
var arr [5]int
s := arr[:]这个过程就类似下面的代码
var arr [5]int
var s runtime.slice
s.array = &arr
s.len = len
s.cap = capgo 会直接将该数组作为切片的底层数组,所以修改切片中的数据也会影响到数组的数据。在使用数组创建切片时,长度大小等于hight-low,容量等于max-low,其中max默认为数组长度,或者也可以在切割的时候手动指定容量,例如。
var arr [5]int
s := arr[2:3:4]
访问
访问切片就跟访问数组一样使用下标索引
elem := s[i]切片的访问操作是在编译期间就已经完成了,通过生成中间代码的方式来访问,最终生成的代码可以理解为下面的伪代码
p := s.ptr
e := *(p + sizeof(elem(s)) * i)实际上是通过移动指针操作来访问对应下标元素的,对应cmd/compile/internal/ssagen.exprCheckPtr函数中的如下部分代码
case ir.OINDEX:
n := n.(*ir.IndexExpr)
switch {
case n.X.Type().IsSlice():
// 偏移指针
p := s.addr(n)
return s.load(n.X.Type().Elem(), p)在通过len和cap函数访问切片的长度和容量时,也是同样的道理,也是对应cmd/compile/internal/ssagen.exprCheckPtr函数中的部分代码
case ir.OLEN, ir.OCAP:
n := n.(*ir.UnaryExpr)
switch {
case n.X.Type().IsSlice():
op := ssa.OpSliceLen
if n.Op() == ir.OCAP {
op = ssa.OpSliceCap
}
return s.newValue1(op, types.Types[types.TINT], s.expr(n.X))在实际生成的代码中,通过移动指针来访问切片结构体中的len字段,可以理解为下面的伪代码
p := &s
len := *(p + 8)
cap := *(p + 16)假如现在有如下代码
func lenAndCap(s []int) (int, int) {
l := len(s)
c := cap(s)
return l, c
}那么在生成中的某个阶段的中间代码大概率长这样
v9 (+9) = ArgIntReg <int> {s+8} [1] : BX (l[int], s+8[int])
v10 (+10) = ArgIntReg <int> {s+16} [2] : CX (c[int], s+16[int])
v1 (?) = InitMem <mem>
v3 (11) = Copy <int> v9 : AX
v4 (11) = Copy <int> v10 : BX
v11 (+11) = MakeResult <int,int,mem> v3 v4 v1 : <>
Ret v11 (+11)
name l[int]: v9
name c[int]: v10
name s+16[int]: v10
name s+8[int]: v9从上面大致就能看出来,一个加 8,一个加 16,很显然是通过指针偏移来访问的切片字段。
倘若能在编译期间推断出它的长度和容量,就不会在运行时偏移指针来获取值,比如下面这种情况就不需要移动指针。
s := make([]int, 10, 20)
l := len(s)
c := cap(s)变量 l和s的值会被直接替换成10和20。
写入
修改
s := make([]int, 10)
s[0] = 100通过索引下标修改切片的值时,在编译期间会通过OpStore操作生成类似如下的伪代码
p := &s
l := *(p + 8)
if !IsInBounds(l,i) {
panic()
}
ptr := (s.ptr + i * sizeof(elem) * i)
*ptr = val在生成中的某个阶段的中间代码大概率长这样
v1 (?) = InitMem <mem>
v5 (8) = Arg <[]int> {s} (s[[]int])
v6 (?) = Const64 <int> [100]
v7 (?) = Const64 <int> [0]
v8 (+9) = SliceLen <int> v5
v9 (9) = IsInBounds <bool> v7 v8
v14 (?) = Const64 <int64> [0]
v12 (9) = SlicePtr <*int> v5
v15 (9) = Store <mem> {int} v12 v6 v1
v11 (9) = PanicBounds <mem> [0] v7 v7 v1
Exit v11 (9)
name s[[]int]: v5
name s[*int]:
name s+8[int]:可以看到代码访问切片长度以检查下标是否合法,最后通过移动指针来存储元素。
添加
通过append函数可以向切片添加元素
var s []int
s = append(s, 1, 2, 3)添加元素后,它会返回一个新的切片结构体,如果没有扩容的话相较于源切片只是更新了长度,否则会的话会指向一个新的数组。有关于append的使用问题在结构这部分已经讲的很详细了,不再过多阐述,下面会关注于append是如何工作的。
在运行时,并没有类似runtime.appendslice这样的函数与之对应,添加元素的工作实际上在编译期就已经做好了,append函数会被展开对应的中间代码,判断的代码在cmd/compile/internal/walk/assign.go walkassign函数中,
case ir.OAPPEND:
// x = append(...)
call := as.Y.(*ir.CallExpr)
if call.Type().Elem().NotInHeap() {
base.Errorf("%v can't be allocated in Go; it is incomplete (or unallocatable)", call.Type().Elem())
}
var r ir.Node
switch {
case isAppendOfMake(call):
// x = append(y, make([]T, y)...)
r = extendSlice(call, init)
case call.IsDDD:
r = appendSlice(call, init) // also works for append(slice, string).
default:
r = walkAppend(call, init, as)
}可以看到分成三种情况
- 添加若干个元素
- 添加一个切片
- 添加一个临时创建的切片
下面会讲一讲生成的代码长什么样,这样明白append实际上是怎么工作的,代码生成的过程如果感兴趣可以自己去了解下。
添加元素
s = append(s, x, y, z)如果只是添加有限个元素,会由walkAppend函数展开成以下代码
// 待添加元素数量
const argc = len(args) - 1
newLen := s.len + argc
// 是否需要扩容
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, newLen, s.cap, argc, elemType)
}
s[s.len - argc] = x
s[s.len - argc + 1] = y
s[s.len - argc + 2] = z首先计算出待添加元素数量,然后判断是否需要扩容,最后再一个个赋值。
添加切片
s = append(s, s1...)如果是直接添加一个切片,会由appendSlice函数展开成以下代码
newLen := s.len + s1.len
// Compare as uint so growslice can panic on overflow.
if uint(newLen) <= uint(s.cap) {
s = s[:newLen]
} else {
s = growslice(s.ptr, s.len, s.cap, s1.len, T)
}
memmove(&s[s.len-s1.len], &s1[0], s1.len*sizeof(T))还是跟之前一样,计算新长度,判断是否需要扩容,不同的是 go 并不会一个个去添加源切片的元素,而是选择直接复制内存。
添加临时切片
s = append(s, make([]T, l2)...)如果是添加一个临时创建的切片,会由extendslice函数展开成以下代码
if l2 >= 0 {
// Empty if block here for more meaningful node.SetLikely(true)
} else {
panicmakeslicelen()
}
s := l1
n := len(s) + l2
if uint(n) <= uint(cap(s)) {
s = s[:n]
} else {
s = growslice(T, s.ptr, n, s.cap, l2, T)
}
// clear the new portion of the underlying array.
hp := &s[len(s)-l2]
hn := l2 * sizeof(T)
memclr(hp, hn)对于临时添加的切片,go 会获取临时切片的长度,如果当前切片的容量不足以足以容纳,就会尝试扩容,完事后还会清除对应部分的内存。
扩容
由结构部分的内容可以得知,切片的底层依旧是一个数组,数组是一个长度固定的数据结构,但切片长度是可变的。切片在数组容量不足时,会申请一片更大的内存空间来存放数据,也就是一个新的数组,再将旧数据拷贝过去,然后切片的引用就会指向新数组,这个过程就被称为扩容。扩容的工作在运行时由runtime.growslice函数来完成,其函数签名如下
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice参数的简单解释
oldPtr,指向旧数组的指针newLen,新数组的长度,newLen = oldLen + numoldCap,旧切片的容量,也就等于旧数组的长度et,元素类型
它的返回值返回了一个新的切片,新切片跟原来的切片毫不相干,唯一共同点就是保存的数据是一样的。
var s []int
s = append(s, elems...)在使用append添加元素时,会要求将其返回值覆盖原切片,如果发生了扩容的话,返回的就是一个新切片了。
在扩容时,首先需要确定新的长度和容量,对应下面的代码
oldLen := newLen - num
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.Size_ == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
// 双倍容量
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
for 0 < newcap && newcap < newLen {
// newcap += 0.25 * newcap + 192
newcap += (newcap + 3*threshold) / 4
}
// 数值溢出了
if newcap <= 0 {
newcap = newLen
}
}
}由上面的代码可知,对于容量小于 256 的切片,容量增长一倍,而容量大于等于 256 的切片,则至少会是原容量的 1.25 倍,当前切片较小时,每次都直接增大一倍,可以避免频繁的扩容,当切片较大时,扩容的倍率就会减小,避免申请过多的内存而造成浪费。
得到新长度和容量后,再计算所需内存,对应如下代码
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
...
...
default:
lenmem = uintptr(oldLen) * et.Size_
newlenmem = uintptr(newLen) * et.Size_
capmem, overflow = math.MulUintptr(et.Size_, uintptr(newcap))
capmem = roundupsize(capmem)
// 最终的容量
newcap = int(capmem / et.Size_)
capmem = uintptr(newcap) * et.Size_
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}内存计算公式就是mem = cap * sizeof(et),为了方便内存对齐,过程中会将计算得到的内存向上取整为 2 的整数次方,并再次计算新容量。如果说新容量太大导致计算时数值溢出,或者说新内存超过了可以分配的最大内存,就会panic。
var p unsafe.Pointer
// 分配内存
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}计算出所需结果后,就分配指定大小的内存,再将newLen到newCap这个区间的内存清空,然后将旧数组的数据拷贝到新切片中,最后构建切片结构体。
拷贝
src := make([]int, 10)
dst := make([]int, 20)
copy(dst, src)当使用copy函数拷贝切片时,会由cmd/compile/internal/walk.walkcopy在编译期间生成的代码决定以何种方式拷贝,如果是在运行时调用,就会用到函数runtime.slicecopy,该函数负责拷贝切片,函数签名如下
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int它接收源切片和目的切片的指针和长度,以及要拷贝的长度width。这个函数的逻辑十分简单,如下所示
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
if fromLen == 0 || toLen == 0 {
return 0
}
n := fromLen
if toLen < n {
n = toLen
}
if width == 0 {
return n
}
// 计算要复制的字节数
size := uintptr(n) * width
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr)
} else {
memmove(toPtr, fromPtr, size)
}
return n
}width的取值,取决于两个切片的长度最小值。可以看到的是,在复制切片的时候并不是一个个遍历元素去复制的,而是选择了直接把底层数组的内存整块复制过去,当切片很大时拷贝内存带来性能的影响并不小。
倘若不是在运行时调用,就会展开成如下形式的代码
n := len(a)
if n > len(b) {
n = len(b)
}
if a.ptr != b.ptr {
memmove(a.ptr, b.ptr, n*sizeof(elem(a)))
}两种方式的原理都是一样的,都是通过拷贝内存的方式拷贝切片。memmove函数是由汇编实现的,感兴趣可以去runtime/memmove_amd64.s 浏览细节。
清空
package main
func main() {
s := make([]int, 0, 10)
s = append(s, 1, 2, 3, 4, 5)
clear(s)
}在版本go1.21中,新增了内置函数clear函数可以用于清空切片的内容,或者说是将所有元素都置为零值。当clear函数作用于切片时,编译器会在编译期间由cmd/compile/internal/walk.arrayClear函数展开成下面这种形式
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
}首先判断切片长度是否为 0,然后计算需要清理的字节数,再根据元素是否是指针分成两种情况来处理,但最终都会用到memclrNoHeapPointers函数,其签名如下。
func memclrNoHeapPointers(ptr unsafe.Pointer, n uintptr)它接收两个参数,一个是指向起始地址的真,另一个就是偏移量,也就是要清理的字节数。内存起始地址为切片所持有的引用的地址,偏移量n = sizeof(et) * len,该函数是由汇编实现,感兴趣可以去runtime/memclr_amd64.s查看细节。
值得一提的是,如果源代码中尝试使用遍历来清空数组,例如这种
for i := range s {
s[i] = ZERO_val
}在没有clear函数之前,通常都是这样来清空切片。在编译时,现在这段代码会被cmd/compile/internal/walk.arrayRangeClear函数优化成这种形式
for i, v := range s {
if len(s) != 0 {
hp = &s[0]
hn = len(s)*sizeof(elem(s))
if elem(s).hasPointer() {
memclrHasPointers(hp, hn)
}else {
memclrNoHeapPointers(hp, hn)
}
// 停止循环
i = len(s) - 1
}
}逻辑还是跟上面的一模一样,其中多了一行i = len(s)-1,其作用是为了在内存清除以后停止循环。
遍历
for i, e := range s {
fmt.Println(i, e)
}在使用for range遍历切片时,会由cmd/compile/internal/walk/range.go中的walkRange函数展开成如下形式
// 拷贝结构体
hs := s
// 获取底层数组指针
hu = uintptr(unsafe.Pointer(hs.ptr))
v1 := 0
v2 := zero
for i := 0; i < hs.len; i++ {
hp = (*T)(unsafe.Pointer(hu))
v1, v2 = i, *hp
... body of loop ...
hu = uintptr(unsafe.Pointer(hp)) + elemsize
}可以看到的是,for range的实现依旧是通过移动指针来遍历元素的。为了避免在遍历时切片被更新,事先拷贝了一份结构体hs,为了避免遍历结束后指针指向越界的内存,hu使用的uinptr类型来存放地址,在需要访问元素的时候才转换成unsafe.Pointer。
变量v2也就是for range中的e,在整个遍历过程中从始至终都是一个变量,它只会被覆盖,不会重新创建。这一点引发了困扰 go 开发者十年的循环变量问题,到了版本go.1.21官方才终于决定要打算解决,预计在后面版本的更新中,v2的创建方式可能会变成下面这样。
v2 := *hp构造中间代码过程这里省略了,这并不属于切片范围的知识,感兴趣可以自己去了解下。