CGO
CGO
由于 go 需要 GC,对于一些性能要求更高的场景,go 可能不太适合处理,c 作为传统的系统编程语言性能是非常优秀的,而 cgo 可以将两者联系起来,相互调用,让 go 调用 c,将性能敏感的任务交给 c 去完成,go 负责处理上层逻辑,cgo 同样支持 c 调用 go,不过这种场景比较少见,也不太建议这么做。
提示
文中代码演示的环境是 win10,命令行用的是gitbash,windows 用户建议提前安装好 mingw。
关于 cgo,官方有一个简单的介绍:C? Go? Cgo! - The Go Programming Language,如果想要更详细的介绍,可以在标准库cmd/cgo/doc.go中获取更加详细的信息,或者也可以直接看文档cgo command - cmd/cgo - Go Packages,两者内容是完全一样的。
代码调用
看下面一个例子
package main
//#include <stdio.h>
import "C"
func main() {
C.puts(C.CString("hello, cgo!"))
}想要使用 cgo 特性,通过导入语句import "C"即可开启,需要注意的是C必须是大写字母,且导入名称无法被重写,同时需要确保环境变量CGO_ENABLED是否设置为1,在默认情况下该环境变量是默认启用的。
$ go env | grep CGO
$ go env -w CGO_ENABLED=1除此之外,还需要确保本地拥有C/C++的构建工具链,也就是gcc,在 windows 平台就是mingw,这样才能确保程序正常通过编译。执行如下命令进行编译,开启了 cgo 以后编译时间是要比纯 go 要更久的。
$ go build -o ./ main.go
$ ./main.exe
hello, cgo!另外要注意的一个点就是,开启 cgo 以后,将无法支持交叉编译。
go 嵌入 c 代码
cgo 支持直接把 c 代码写在 go 源文件中,然后直接调用,看下面的例子,例子中编写了一个名为printSum的函数,然后在 go 中的main函数进行调用。
package main
/*
#include <stdio.h>
void printSum(int a, int b) {
printf("c:%d+%d=%d",a,b,a+b);
}
*/
import "C"
func main() {
C.printSum(C.int(1), C.int(2))
}输出
c:1+2=3这适用于简单的场景,如果 c 代码非常多,跟 go 代码糅杂在一起十分降低可读性,就不太适合这么做。
错误处理
在 go 语言中错误处理以返回值的形式返回,但 c 语言不允许有多返回值,为此可以使用 c 中的errno,表示在函数调用期间发生了错误,cgo 对此做了兼容,在调用 c 函数时可以像 go 一样用返回值来处理错误。要使用errno,首先引入errno.h,看下面的一个例子
package main
/*
#include <stdio.h>
#include <stdint.h>
#include <errno.h>
int32_t sum_positive(int32_t a, int32_t b) {
if (a <= 0 || b <= 0) {
errno = EINVAL;
return 0;
}
return a + b;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
sum, err := C.sum_positive(C.int32_t(0), C.int32_t(1))
if err != nil {
fmt.Println(reflect.TypeOf(err))
fmt.Println(err)
return
}
fmt.Println(sum)
}输出
syscall.Errno
The device does not recognize the command.可以看到它的错误类型是syscall.Errno,errno.h中还定义了其它很多错误代码,可以自己去了解。
go 引入 c 文件
通过引入 c 文件,就可以很好的解决上述的问题,首先创建一个头文件sum.h,内容如下
int sum(int a, int b);然后再创建sum.c,编写具体的函数
#include "sum.h"
int sum(int a, int b) {
return a + b;
}然后在main.go中导入头文件
package main
//#include "sum.h"
import "C"
import "fmt"
func main() {
res := C.sum(C.int(1), C.int(2))
fmt.Printf("cgo sum: %d\n", res)
}现在进行编译的话,必须要指定当前文件夹,否则找不到 c 文件,如下
$ go build -o sum.exe . && ./sum.exe
cgo sum: 3代码中res是 go 中的一个变量,C.sum是 c 语言中的函数,它的返回值是 c 语言中的int而非 go 中的int,之所以能成功调用,是因为 cgo 从中做了类型转换。
c 调用 go
c 调用 go,指的是在 cgo 中 c 调用 go,而非原生的 c 程序调用 go,它们是这样一个调用链go-cgo-c->cgo->go。go 调用 c 是为了利用 c 的生态和性能,几乎没有原生的 c 程序调用 go 这种需求,如果有的话也建议通过网络通信来代替。
cgo 支持导出 go 函数让 c 调用,如果要导出 go 函数,需在函数签名上方加上//export func_name注释,并且其参数和返回值都得是 cgo 支持的类型,例子如下
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}改写刚刚的sum.c文件为如下内容
#include <stdint.h>
#include <stdio.h>
#include "sum.h"
#include "_cgo_export.h"
extern int32_t sum(int32_t a, int32_t b);
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}同时修改头文件sum.h
void do_sum();然后在 go 中导出函数
package main
/*
#include <stdio.h>
#include <stdint.h>
#include "sum.h"
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}现在 c 中使用的sum函数实际上是 go 提供的,输出结果如下
20关键点在于sum.c文件中导入的_cgo_export.h,它包含了有关所有 go 导出的类型,如果不导入的话就无法使用 go 导出的函数。另一个注意点是_cgo_export.h不能在 go 文件导入,因为该头文件生成的前提是所有 go 源文件能够通过编译。因此下面这种写法是错误的
package main
/*
#include <stdint.h>
#include <stdio.h>
#include "_cgo_export.h"
void do_sum() {
int32_t a = 10;
int32_t b = 10;
int32_t c = sum(a, b);
printf("%d", c);
}
*/
import "C"
func main() {
C.do_sum()
}
//export sum
func sum(a, b C.int32_t) C.int32_t {
return a + b
}编译器会提示头文件不存在
fatal error: _cgo_export.h: No such file or directory
#include "_cgo_export.h"
^~~~~~~~~~~~~~~
compilation terminated.倘若 go 函数具有多个返回值,那么 c 调用时将返回一个结构体。
顺带一提,我们可以把 go 指针通过 c 函数参数传递给 c,在 c 函数调用期间 cgo 会尽量保证内存安全,但是导出的 go 函数返回值不能带指针,因为在这种情况下 cgo 没法判断其是否被引用,也不好固定内存,如果返回的内存被引用了,然后在 go 中这段内存被 GC 掉了或者发生偏移,将导致指针越界,如下所示。
//export newCharPtr
func newCharPtr() *C.char {
return new(C.char)
}上面的写法默认是不允许通过编译的,如果想要关闭这个检查,可以如下设置。
GODEBUG=cgocheck=0它有两种检查级别,可以设为1,2,级别越高检查造成运行时开销越大,可以 前往cgo command - passing_pointer了解细节。
类型转换
cgo 对 c 与 go 之间的类型做了一个映射,方便它们在运行时调用。对于 c 中的类型,在 go 中导入import "C"之后,大部分情况下可以通过
C.typename这种方式来直接访问,比如
C.int(1)
C.char('a')但 c 语言类型可以由多个关键字组成,比如
unsigned char这种情况就没法直接访问了,不过可以使用 c 中的typedef关键字来给类型取个别名,其功能等同于 go 中的类型别名。如下
typedef unsigned char byte;这样一来,就可以通过C.byte来访问类型unsigned char了。例子如下
package main
/*
#include <stdio.h>
typedef unsigned char byte;
void printByte(byte b) {
printf("%c\n",b);
}
*/
import "C"
func main() {
C.printByte(C.byte('a'))
C.printByte(C.byte('b'))
C.printByte(C.byte('c'))
}输出
a
b
c大部分情况下,cgo 给常用类型(基本类型之类的)已经取好了别名,也可以根据上述的方法自己定义,不会冲突。
char
c 中的char对应 go 中的int8类型,unsigned char对应 go 中的uint8也就是byte类型。
package main
/*
#include <stdio.h>
#include<complex.h>
char ch;
char get() {
return ch;
}
void set(char c) {
ch = c;
}
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
C.set(C.char('c'))
res := C.get()
fmt.Printf("type: %s, val: %v", reflect.TypeOf(res), res)
}输出
type: main._Ctype_char, val: 99如果将set的参数换成C.char(math.MaxInt8 + 1),那么编译就会失败,并提示如下错误
cannot convert math.MaxInt8 + 1 (untyped int constant 128) to type _Ctype_char字符串
cgo 提供了一些伪函数用于在 c 和 go 之间传递字符串和字节切片,这些函数实际上并不存在,你也没法找到它们的定义,就跟import "C"一样,C这个包也是不存在的,只是为了方便开发者使用,在编译后它们会被转换成其它的操作。
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []bytego 中的字符串本质上是一个结构体,里面持有着一个底层数组的引用,在传递给 c 函数时,需要使用C.CString()在 c 中使用malloc创建一个“字符串”,为其分配内存空间,然后返回一个 c 指针,因为 c 中没有字符串这个类型,通常会使用char*来表示字符串,也就是一个字符数组的指针,使用完毕后记得使用free释放内存。
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cstring := C.CString("this is a go string")
C.printfGoString(cstring)
C.free(unsafe.Pointer(cstring))
}也可以是char数组类型,两者其实都一样,都是指向头部元素的指针。
void printfGoString(char s[]) {
puts(s);
}也可以传递字节切片,由于C.CBytes()会返回一个unsafe.Pointer,在传递给 c 函数之前要将其转换为*C.char类型。
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
cbytes := C.CBytes([]byte("this is a go string"))
C.printfGoString((*C.char)(cbytes))
C.free(unsafe.Pointer(cbytes))
}上面的例子输出都是一样的
this is a go string上述这几种字符串传递方法涉及到了一次内存拷贝,在传递过后实际上是在 c 内存和 go 内存中各自保存了一份,这样做会更安全。话虽如此,我们依然可以直接传递指针给 c 函数,也可以在 c 中直接修改 go 中的字符串,看下面的例子
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s) {
puts(s);
}
*/
import "C"
import "unsafe"
func main() {
ptr := unsafe.Pointer(unsafe.SliceData([]byte("this is a go string")))
C.printfGoString((*C.char)(ptr))
}输出
this is a go string例子通过unsafe.SliceData直接获取了字符串底层数组的指针,并将其转换为了 c 指针后传递给 c 函数,该字符串的内存是由 go 进行管理的,自然也就不再需要 free,这样做的好处就是传递的过程不再需要拷贝,但有一定的风险。下面的例子演示了在 c 中修改 go 中的字符串
package main
/*
#include <stdio.h>
#include <stdlib.h>
void printfGoString(char* s, int len) {
puts(s);
s[8] = 'c';
puts(s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var buf []byte
buf = []byte("this is a go string")
ptr := unsafe.Pointer(unsafe.SliceData(buf))
C.printfGoString((*C.char)(ptr), C.int(len(buf)))
fmt.Println(string(buf))
}输出
this is a go string
this is c go string
this is c go string整数
go 与 c 之间的整数映射关系如下表所示,关于整数的类型映射还在可以在标准库cmd/cgo/gcc.go看到一些相关信息。
| go | c | cgo |
|---|---|---|
| int8 | singed char | C.schar |
| uint8 | unsigned char | C.uchar |
| int16 | short | C.short |
| uint16 | unsigned short | C.ushort |
| int32 | int | C.int |
| uint32 | unsigned int | C.uint |
| int32 | long | C.long |
| uint32 | unsigned long | C.ulong |
| int64 | long long int | C.longlong |
| uint64 | unsigned long long int | C.ulonglong |
示例代码如下
package main
/*
#include <stdio.h>
void printGoInt8(signed char n) {
printf("%d\n",n);
}
void printGoUInt8(unsigned char n) {
printf("%d\n",n);
}
void printGoInt16(signed short n) {
printf("%d\n",n);
}
void printGoUInt16(unsigned short n) {
printf("%d\n",n);
}
void printGoInt32(signed int n) {
printf("%d\n",n);
}
void printGoUInt32(unsigned int n) {
printf("%d\n",n);
}
void printGoInt64(signed long long int n) {
printf("%ld\n",n);
}
void printGoUInt64(unsigned long long int n) {
printf("%ld\n",n);
}
*/
import "C"
func main() {
C.printGoInt8(C.schar(1))
C.printGoInt8(C.schar(1))
C.printGoInt16(C.short(1))
C.printGoUInt16(C.ushort(1))
C.printGoInt32(C.int(1))
C.printGoUInt32(C.uint(1))
C.printGoInt64(C.longlong(1))
C.printGoUInt64(C.ulonglong(1))
}cgo 同时也对<stdint.h>的整数类型提供了支持,这里的类型内存大小更为清晰明确,而且其命名风格也与 go 非常相似。
| go | c | cgo |
|---|---|---|
| int8 | int8_t | C.int8_t |
| uint8 | uint8_t | C.uint8_t |
| int16 | int16_t | C.int16_t |
| uint16 | uint16_t | C.uint16_t |
| int32 | int32_t | C.int32_t |
| uint32 | uint32_t | C.uint32_t |
| int64 | int64_t | C.int64_t |
| uint64 | uint64_t | C.uint64_t |
在使用 cgo 时,建议使用<stdint.h>中的整数类型。
浮点数
go 与 c 的浮点数类型映射如下
| go | c | cgo |
|---|---|---|
| float32 | float | C.float |
| float64 | double | C.double |
代码示例如下
package main
/*
#include <stdio.h>
void printGoFloat32(float n) {
printf("%f\n",n);
}
void printGoFloat64(double n) {
printf("%lf\n",n);
}
*/
import "C"
func main() {
C.printGoFloat32(C.float(1.11))
C.printGoFloat64(C.double(3.14))
}切片
切片的情况的实际上跟上面讲到的字符串差不多,不过区别在于 cgo 没有提供伪函数来对切片进行拷贝,想让 c 访问到 go 中的切片就只能把切片的指针传过去。看下面的一个例子
package main
/*
#include <stdio.h>
#include <stdint.h>
void printInt32Arr(int32_t* s, int32_t len) {
for (int32_t i = 0; i < len; i++) {
printf("%d ", s[i]);
}
}
*/
import "C"
import (
"unsafe"
)
func main() {
var arr []int32
for i := 0; i < 10; i++ {
arr = append(arr, int32(i))
}
ptr := unsafe.Pointer(unsafe.SliceData(arr))
C.printInt32Arr((*C.int32_t)(ptr), C.int(len(arr)))
}输出
0 1 2 3 4 5 6 7 8 9这里将切片的底层数组的指针传递给了 c 函数,由于该数组的内存是由 go 管理,不建议 c 长期持有其指针引用。反过来,将 c 的数组作为 go 切片的底层数组的例子如下
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t s[] = {1, 2, 3, 4, 5, 6, 7};
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
l := unsafe.Sizeof(C.s) / unsafe.Sizeof(C.s[0])
fmt.Println(l)
goslice := unsafe.Slice(&C.s[0], l)
for i, e := range goslice {
fmt.Println(i, e)
}
}输出
7
0 1
1 2
2 3
3 4
4 5
5 6
6 7通过unsafe.Slice函数可以将数组指针转换为切片,按照直觉来说,c 中的数组就是一个指向头部元素的指针,按照常理来说应该这样使用
goslice := unsafe.Slice(&C.s, l)通过输出可以看到,如果这样做的话,除了第一个元素,剩下的内存全都越界了。
0 [1 2 3 4 5 6 7]
1 [0 -1 0 0 0 3432824 0]
2 [0 0 -1 -1 0 0 -1]
3 [0 0 0 255 0 0 0]
4 [2 0 0 0 3432544 0 0]
5 [0 3432576 0 3432592 0 3432608 0]
6 [0 0 3432624 0 0 0 1422773729]即便 c 中的数组只是一个头指针,经过 cgo 包裹了一下就成了 go 数组,有了自己的地址,所以应该对数组头部元素取址。
goslice := unsafe.Slice(&C.s[0], l)结构体
通过C.struct_前缀加上结构体名称,就可以访问 c 结构体,c 结构体无法被当作匿名结构体嵌入 go 结构体。下面是一个简单的 c 结构体的例子
package main
/*
#include <stdio.h>
#include <stdint.h>
struct person {
int32_t age;
char* name;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var p C.struct_person
p.age = C.int32_t(18)
p.name = C.CString("john")
fmt.Println(reflect.TypeOf(p))
fmt.Printf("%+v", p)
}输出
main._Ctype_struct_person
{age:18 name:0x1dd043b6e30}如果 c 结构体的某些成员包含bit-field,cgo 就会忽略这类结构体成员,比如将person修改为下面这种
struct person {
int32_t age: 1;
char* name;
};再次执行就会报错
p.age undefined (type _Ctype_struct_person has no field or method age)c 和 go 的结构体字段的内存对齐规则并不相同,如果开启了 cgo,大部分情况下会以 c 为主导。
联合体
使用C.union_加上名称就可以访问 c 中的联合体,由于 go 并不支持联合体,它们在 go 中会以字节数组的形式存在。下面是一个简单的例子
package main
/*
#include <stdio.h>
#include <stdint.h>
union data {
int32_t age;
char ch;
};
*/
import "C"
import (
"fmt"
"reflect"
)
func main() {
var u C.union_data
fmt.Println(reflect.TypeOf(u), u)
}输出
[4]uint8 [0 0 0 0]通过unsafe.Pointer可以进行访问和修改
func main() {
var u C.union_data
ptr := (*C.int32_t)(unsafe.Pointer(&u))
fmt.Println(*ptr)
*ptr = C.int32_t(1024)
fmt.Println(*ptr)
fmt.Println(u)
}输出
0
1024
[0 4 0 0]枚举
通过前缀C.enum_加上枚举类型名就可以访问 c 中的枚举类型。下面是一个简单的例子
package main
/*
#include <stdio.h>
#include <stdint.h>
enum player_state {
alive,
dead,
};
*/
import "C"
import "fmt"
type State C.enum_player_state
func (s State) String() string {
switch s {
case C.alive:
return "alive"
case C.dead:
return "dead"
default:
return "unknown"
}
}
func main() {
fmt.Println(C.alive, State(C.alive))
fmt.Println(C.dead, State(C.dead))
}输出
0 alive
1 dead指针
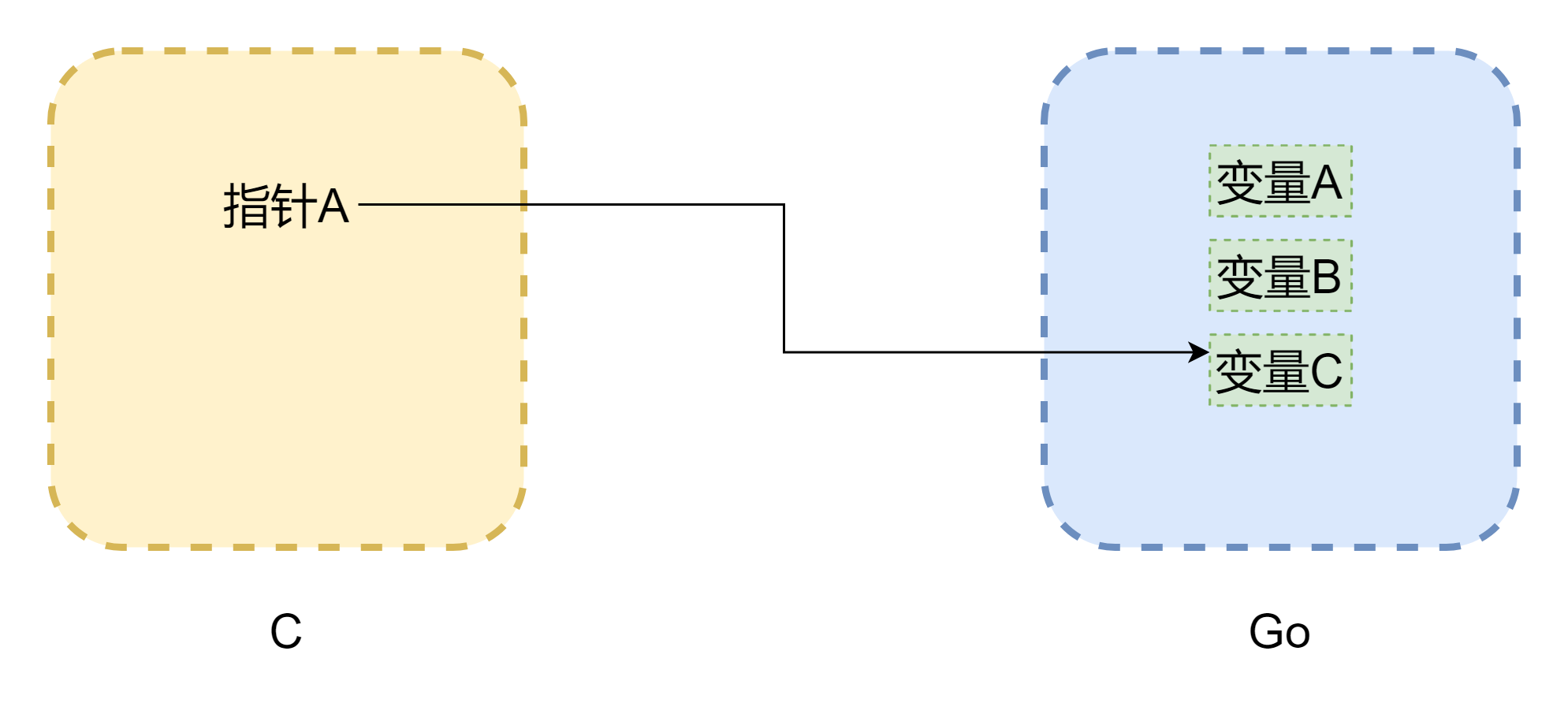
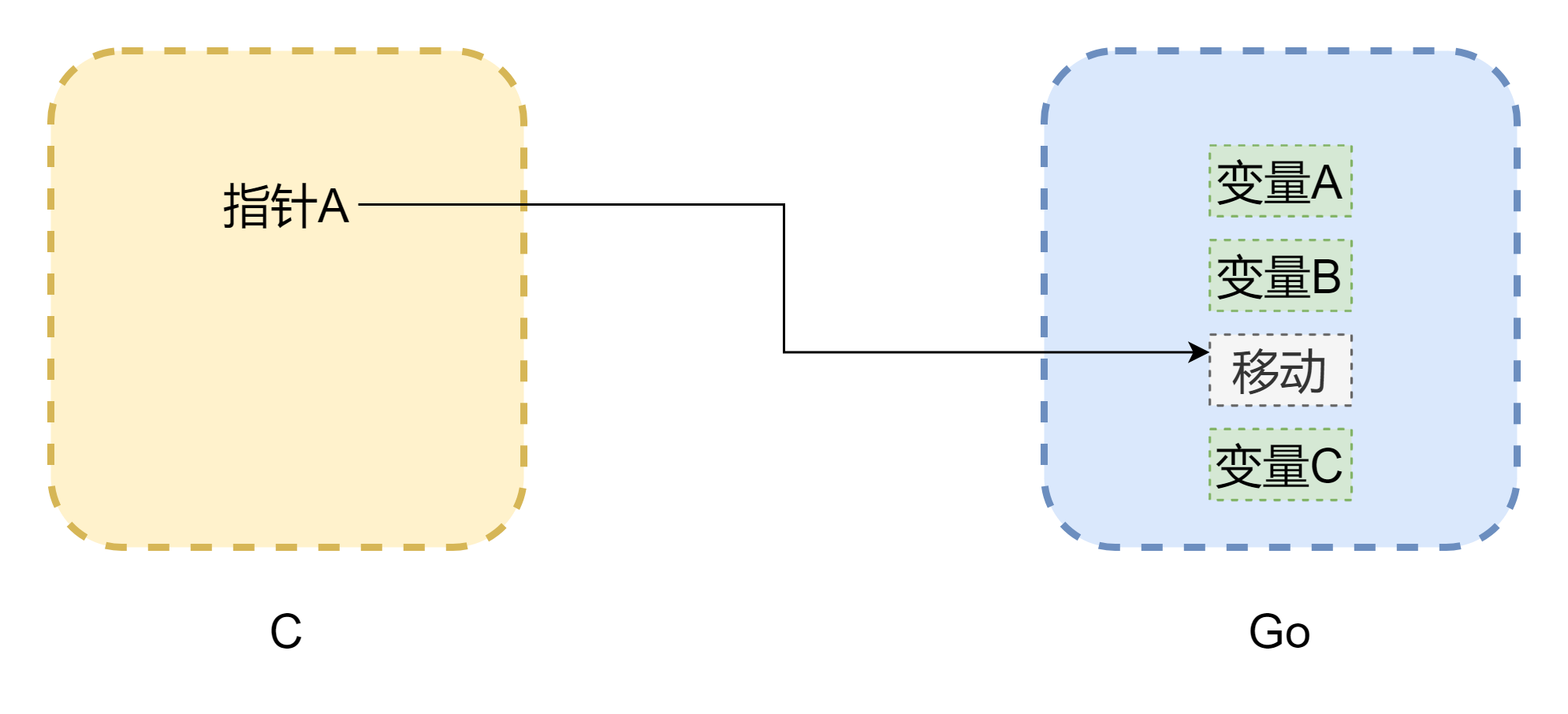
谈到了指针避不开内存,cgo 之间相互调用最大的问题就是两门语言的内存模型并不相同,c 语言的内存完全是由开发者手动管理,用malloc()分配内存,free()释放内存,如果不去手动释放,它是绝对不会自己释放掉的,所以 c 的内存管理是非常稳定的。而 go 就不一样了,它带有 GC,并且 Goroutine 的栈空间是会动态调整的,当栈空间不足时会进行增长,那么这样一来,内存地址就可能发生了变化,跟上图一样(图画的并不严谨),指针可能就成了 c 中常见的悬挂指针。即便 cgo 在大多数情况可以避免内存移动(由runtime.Pinner来固定内存),但 go 官方也不建议在 c 中长期引用 go 的内存。但是反过来,go 中的指针引用 c 中的内存的话,是比较安全的,除非手动调用C.free(),否则这块内存是不会被自动释放掉的。
如果要在 c 和 go 之间传递指针,就需要先将其转为unsafe.Pointer,然后再转换成对应的指针类型,就跟 c 中的void*一样。看两个例子,第一个是 c 指针引用 go 变量的例子,而且还对变量做了修改。
package main
/*
#include <stdio.h>
#include <stdint.h>
void printNum(int32_t* s) {
printf("%d\n", *s);
*s = 3;
printf("%d\n", *s);
}
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
var num int32 = 1
ptr := unsafe.Pointer(&num)
C.printNum((*C.int32_t)(ptr))
fmt.Println(num)
}输出
1
3
3第二个是 go 指针引用 c 变量,并对其修改的例子。
package main
/*
#include <stdio.h>
#include <stdint.h>
int32_t num = 10;
*/
import "C"
import (
"fmt"
"unsafe"
)
func main() {
fmt.Println(C.num)
ptr := unsafe.Pointer(&C.num)
iptr := (*int32)(ptr)
*iptr++
fmt.Println(C.num)
}输出
10
11顺带一提,cgo 不支持 c 中的函数指针。
链接库
c 语言并没有像 go 这样的依赖管理,想要直接使用别人写好的库除了直接获取源代码之外,还有个办法就是静态链接库和动态链接库,cgo 也支持这些,得益于此,我们就可以在 go 程序中导入别人写好的库,而不需要源代码。
动态链接库
动态链接库无法单独运行,它在运行时会与可执行文件一起加载到内存中,下面演示制作一个简单的动态链接库,并使用 cgo 进行调用。首先准备一个lib/sum.c文件,内容如下
#include <stdint.h>
int32_t sum(int32_t a, int32_t b) {
return a + b;
}编写头文件lib/sum.h
#include <stdint.h>
int sum(int32_t a, int32_t b);接下来使用gcc来制作动态链接库,首先编译生成目标文件
$ cd lib
$ gcc -c sum.c -o sum.o然后制作动态链接库
$ gcc -shared -o libsum.dll sum.o制作完成后,然后在 go 代码中引入sum.h头文件,并且还得通过宏告诉 cgo 去哪里寻找库文件
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}CFLAGS: -I指的是搜索头文件的相对路径,-L指的是库搜索路径,${SRCDIR}代指当前路径的绝对路径,因为它的参数必须是绝对路径-l指的是库文件的名称,sum 就是sum.dll。
CFFLAGS和LDFLAGS这两个都是 gcc 的编译选项,出安全考虑,cgo 禁用了一些参数,前往cgo command了解细节。
把动态库放到exe的同级目录下
$ ls
go.mod go.sum lib/ libsum.dll* main.exe* main.go最后编译 go 程序并执行
$ go build main.go && ./main.exe
3到此动态链接库调用成功。
静态链接库
不同于动态链接库,使用 cgo 导入静态链接库时,它会与 go 的目标文件最终链接成一个可执行文件。还是拿sum.c举例,先将源文件编译成目标文件
$ gcc -o sum.o -c sum.c然后将目标文件打包成静态链接库(必须是lib前缀开头,不然会找不到)
$ ar rcs libsum.a sum.ogo 文件内容
package main
/*
#cgo CFLAGS: -I ./lib
#cgo LDFLAGS: -L${SRCDIR}/lib -llibsum
#include "sum.h"
*/
import "C"
import "fmt"
func main() {
res := C.sum(C.int32_t(1), C.int32_t(2))
fmt.Println(res)
}编译
$ go build && ./main.exe
3到此,静态链接库调用成功。
最后
虽然使用 cgo 的出发点是为了性能,但在 c 与 go 之间切换也会不小的造成性能损失,对于一些十分简单的任务,cgo 的效率并不如纯 go。看一个例子
package main
/*
#include <stdint.h>
int32_t cgo_sum(int32_t a, int32_t b) {
return a + b;
}
*/
import "C"
import (
"fmt"
"time"
)
func go_sum(a, b int32) int32 {
return a + b
}
func testSum(N int, do func()) int64 {
var sum int64
for i := 0; i < N; i++ {
start := time.Now()
do()
sum += time.Now().Sub(start).Nanoseconds()
}
return sum / int64(N)
}
func main() {
N := 1000_000
nsop1 := testSum(N, func() {
C.cgo_sum(C.int32_t(1), C.int32_t(2))
})
fmt.Printf("cgo_sum: %d ns/op\n", nsop1)
nsop2 := testSum(N, func() {
go_sum(1, 2)
})
fmt.Printf("pure_go_sum: %d ns/op\n", nsop2)
}这是一个非常简单的测试,分别用 c 和 go 编写了一个两数求和的函数,然后各自运行 100w 次,求其平均耗时,测试结果如下
cgo_sum: 49 ns/op
pure_go_sum: 2 ns/op从结果可以看到,cgo 的平均耗时是纯 go 的二十几倍,倘若执行的不是单纯的两数相加,而是一个比较耗时的任务,cgo 的优势会更大一些。除此之外,使用 cgo 还有以下缺点
- 许多 go 配套工具链将无法使用,比如 gotest,pprof,上面的测试例子就不能使用 gotest,只能自己手写。
- 编译速度变慢,自带的交叉编译也没法用了
- 内存安全问题
- 依赖问题,如果别人用了你的库,等于也要开启 cgo。
在没有考虑周全之前,不要在项目中引入 cgo,对于一些十分复杂的任务,使用 cgo 确实可以带来好处,但如果只是一些简单的任务,还是老老实实用 go 吧。