Protobuf
Protobuf
官网:Protocol Buffers | Google Developers
介绍
官方教程:Protocol Buffer Basics: Go | Protocol Buffers | Google Developers
Protocol Buffers是谷歌 2008 年开源的语言无关,协议无关,可扩展的结构化数据序列化机制,在解包封包的时候更加的快速,多用于 RPC 领域通信相关,可以定义数据的结构化方式,然后可以使用特殊生成的源代码轻松地将结构化数据写入各种数据流和从各种数据流中读取结构化数据,并使用于各种语言,关于Protocol Buffers下文统称为protobuf。
protobuf算是比较流行,尤其是 go 这一块,gRPC 就将其作为协议传输的序列化机制。
语法
首先从一个例子来看protobuf文件大体长什么样,总体来说它的语法非常简单,十几分钟就能上手。下面是一个名为search.proto文件的例子,protobuf的文件后缀就是.proto。
syntax = "proto3";
message SearchRequest {
string query = 1;
string number = 2;
}
message SearchResult {
string data = 1;
}
service SearchService {
rpc Search(SearchRequest) returns(SearchResult);
}- 第一行
syntax = "proto3";表示使用proto3的语法,默认使用proto3的语法。 message声明的方式类似于结构体,是proto中的基本结构SearchRequest中定义了三个字段,每个字段都会有名称和类型service中定义了一个服务,一个服务中包含一个或多个 rpc 接口- rpc 接口必须要有且只能有一个参数和返回值,它们的类型必须是
message,不能是基本类型。
另外需要注意的是,proto文件中的每一行末尾必须要有分号结尾。
注释
注释风格跟 go 完全一致。
syntax = "proto3";
/* 注释
* 注释 */
message SearchRequest {
string query = 1; //注释
string number = 2;
}类型
类型修饰只能出现在message中,不能单独出现。
基本类型
| proto Type | Go Type |
|---|---|
| double | float64 |
| float | float32 |
| int32 | int32 |
| int64 | int64 |
| uint32 | uint32 |
| uint64 | uint64 |
| sint32 | int32 |
| sint64 | int64 |
| fixed32 | uint32 |
| fixed64 | uint64 |
| sfixed32 | int32 |
| sfixed64 | int64 |
| bool | bool |
| string | string |
| bytes | []byte |
数组
在基本类型前面加上repeated修饰符表示这是一个数组类型,对应 go 中的切片。
message Company {
repeated string employee = 1;
}map
在 protobuf 中定义 map 类型格式如下
map<key_type, value_type> map_field = N;key_type必须是数字或者字符串,value_type没有类型限制,看一个例子
message Person {
map<string, int64> cards = 1;
}字段
事实上,proto 并不是传统的键值类型,在声明的proto文件中是不会出现具体的数据的,每一次字段的=后面跟的应该是当前message中的唯一编号,这些编号用于在二进制消息体中识别和定义这些字段。编号从 1 开始,1-15 的编号会占用 1 个字节,16-2047 会占用两个字节,因此尽可能的将频繁出现的字段赋予 1-15 的编号以节省空间,并且应该留出一些空间以留给后续可能会频繁出现的字段。
一个message中的字段应当遵循以下规则
singular: 默认是该种类型的字段,在一个结构良好的message中,有且只能由 0 个或者 1 个该字段,即不能重复存在同一个字段。如下声明便会报错。syntax = "proto3"; message SearchRequest { string query = 1; string number = 2; string number = 3;//字段重复 }optional: 与singular类似,只是可以显示的检查字段值是否被设置,可能会有以下两种情况set: 将会被序列化unset: 不会被序列化
repeated: 此种类型的字段可以出现 0 次或多次,将会按照顺序保留重复值(说白了其实就是数组,可以允许同一个类型的值多次重复出现,并且按照出现的顺序保留,就是索引)map: 键值对类型的字段,声明方式如下map<string,int32> config = 3;
保留字段
reserve关键字可以声明保留字段,保留字段编号声明后,将无法再被用作其他字段的编号和名称,编译时也会发生错误。谷歌官方给出的回答是:,如果一个proto文件在新版本中删除了一些编号,那么在未来其他用户可能会重用这些已被删除的编号,但是倘若换回旧版本的编号的话就会造成字段对应的编号不一致从而产生错误,保留字段就可以在编译期起到这么一个提醒作用,提醒你不能使用这个保留使用的字段,否则编译将会不通过。
syntax = "proto3";
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
reserved "a"; //声明具体名称的字段为保留字段
reserved 1 to 2; //声明一个编号序列为保留字段
reserved 3,4; //声明
}如此一来,此文件将不会通过编译。
弃用字段
如果一个字段被弃用,可以如下书写。
message Body {
string name = 1 [deprecated = true];
}枚举
可以声明枚举常量并将其当作字段的类型来使用,需要注意的是,枚举项的第一个元素必须是零,因为枚举项的默认值就是第一个元素。
syntax = "proto3";
enum Type {
GET = 0;
POST = 1;
PUT = 2;
DELETE = 3;
}
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
Type type = 5;
}当枚举项内部存在相同值的枚举项时,可以使用枚举别名
syntax = "proto3";
enum Type {
option allow_alias = true; //需要开启允许使用别名的配置项
GET = 0;
GET_ALIAS = 0; //GET枚举项的别名
POST = 1;
PUT = 2;
DELETE = 3;
}
message SearchRequest {
string query = 1;
string number = 2;
map<string, int32> config = 3;
repeated string a = 4;
Type type = 5;
}嵌套消息
message Outer { // Level 0
message MiddleAA { // Level 1
message Inner { // Level 2
int64 ival = 1;
bool booly = 2;
}
}
message MiddleBB { // Level 1
message Inner { // Level 2
int32 ival = 1;
bool booly = 2;
}
}
}message里面可以嵌套声明message,就跟嵌套结构体一样。
Package
您可以向protobuf文件添加一个可选的包修饰符,以防止协议消息类型之间的名称冲突。
package foo.bar;
message Open { ... }然后,您可以在定义消息类型的字段时使用包名:
message Foo {
...
foo.bar.Open open = 1;
...
}Import
导入可以让多个protobuf文件共享定义,它的语法如下,在导入的时候不能省略文件拓展名。
import "a/b/c.proto";在导入的时候都是使用的相对路径,这个相对路径不是指的导入文件与被导入文件的相对路径,而是取决于protoc编译器生成代码时所指定的扫描路径,假设有如下的文件结构
pb_learn
│ common.proto
│
├─monster
│ monster.proto
│
└─player
health.proto
player.proto如果我们只需要生成player目录部分的代码,并且在扫描路径时仅指定了player目录,那么health.proto与player.proto之间的相互导入可以直接写单文件名,比如player.proto导入health.proto。
import "health.proto";倘若此时player.proto导入了common.proto或monster目录下的文件,那么就会编译失败,所以下面这种写法是完全错误的,因为编译器没法找到这些文件。
import "../common.proto"; // 错误写法提示
顺带一提,..,.这些符号是不允许出现在导入路径中的。
假设在编译时指定了pb_learn为扫描路径,那么就可以通过相对路径来导入其它目录的文件,实际导入的路径就是该文件的绝对地址相对于pb_learn的相对地址,看下面player.proto导入其它文件的例子。
import "common.proto";
imrpot "monster/monster.proto";
import "player/health.proto";即便是处于同一目录下的health.proto此刻也必须要使用相对路径。所以在一个项目中,我们一般会单独创建一个文件夹来存放所有的protobuf文件,并在编译时指定其作为扫描路径,而该目录下的所有导入行为也是基于它的相对路径。
提示
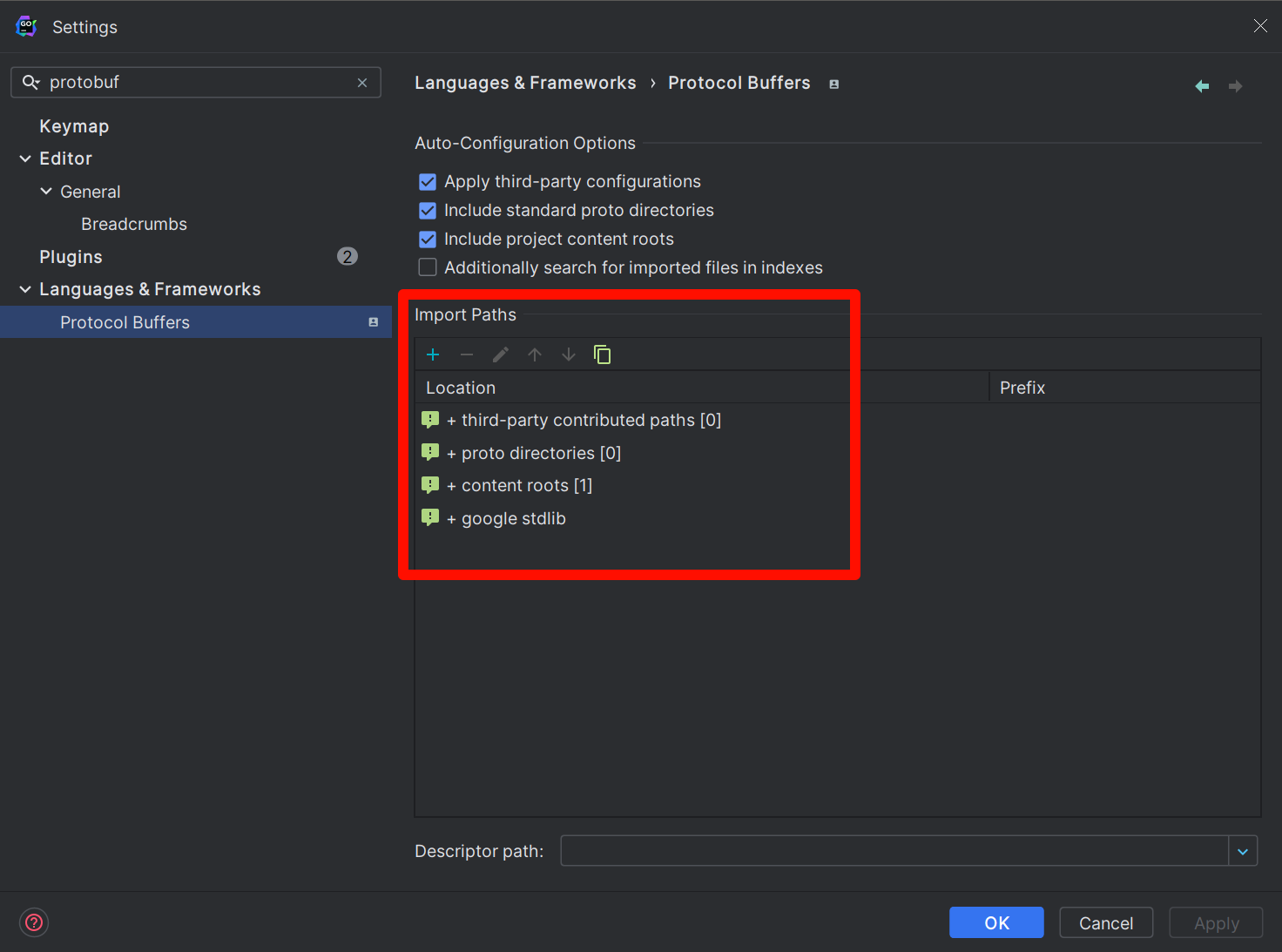
如果你使用的是 goland 编辑器,对于你自己创建的protobuf目录,默认是没法解析的,也就会出现爆红的情况,想要 goland 识别的话就得手动设置扫描路径,其原理跟上面讲的完全一样,设置方法如下,打开如下设置
File | Settings | Languages & Frameworks | Protocol Buffers在Import Paths中手动添加扫描路径,这个扫描路径应该跟你编译时指定的路径是一致的。
Any
Any 类型允许您将消息作为嵌入类型使用,而不需要它们的 proto 定义,我们可以直接导入谷歌定义的类型,它是自带的,不需要手动编写。
import "google/protobuf/any.proto";
message ErrorStatus {
string message = 1;
repeated google.protobuf.Any details = 2;
}谷歌还预定义了其它非常多的类型,前往protobuf/ptypes at master · golang/protobuf (github.com)查看更多,主要有包括
- 基本类型的封装
- 时间类型
- Duration 类型
有关它们的protobuf定义应该在protoc编译器的inlucde目录下。
OneOf
这里的官方文档给出的解释实在是太繁琐了,说人话其实就是表示一个字段在传输时会有多种可能的类型,但最终只可能会有一个类型被使用,它的内部不允许出现repeated修饰的字段,这就好像 c 语言中的union一样。
message Stock {
// Stock-specific data
}
message Currency {
// Currency-specific data
}
message ChangeNotification {
int32 id = 1;
oneof instrument {
Stock stock = 2;
Currency currency = 3;
}
}Service
service关键字可以定义一个 RPC 服务,一个 RPC 服务包含若干个 rpc 接口,接口又分为一元接口和流式接口。
message Body {
string name = 1;
}
service ExampleService {
rpc DoSomething(Body) returns(Body);
}而流式接口又分为单向流式和双向流式,通常用stream关键字来修饰,看下面的一个例子。
message Body {
string name = 1;
}
service ExampleService {
// 客户端流式
rpc DoSomething(stream Body) returns(Body);
// 服务端流式
rpc DoSomething1(Body) returns(stream Body);
// 双向流式
rpc DoSomething2(stream Body) returns(stream Body);
}所谓流式就是就是在一个连接中长期的相互发送数据,而不再像一元接口那样简单的一问一答。
Empty
empty 实际上是一个空的message,对应 go 中的空结构体,它很少用于修饰字段,主要是用来表示某个 rpc 接口不需要参数或者没有返回值。
syntax = "proto3";
import "google/protobuf/empty.proto";
service EmptyService {
rpc Do(google.protobuf.Empty) returns(google.protobuf.Empty);
}Option
option 通常用于控制protobuf的一些行为。比如控制 go 语言源代码生成的包,就可以如下声明。
option go_package = "github/jack/sample/pb_learn;pb_learn"分号前面的是代码生成后其它源文件的导入路径,分号后面的就是对应生成文件的包名。
它可以做一些一些优化,有以下几个可用的值,不可重复声明。
SPEED,优化程度最高,生成的代码体积最大,默认是这个。CODE_SIZE,会减少代码生成的体积,但是会依赖反射进行序列化LIFE_RUNEIMTE,代码体积最小,但是会缺少一些特性。
下面是一个使用案例
option optimize_for = SPEED;除此之外,option 还可以给message和enum添加一些元信息,利用反射可以获取这些信息,这在进行参数校验的时候尤其有用。
编译
编译也就是代码生成,上面只是定义了protobuf文件,实际使用时需要将其转化为某种特定的语言源代码才能使用,我们通过protoc编译器来完成此时,它支持多种语言。
安装
编译器下载的话到protocolbuffers/protobuf: Protocol Buffers - Google's data interchange format (github.com)去下载最新版的 Release,一般是一个压缩文件
protoc-25.1-win64
│ readme.txt
│
├─bin
│ protoc.exe
│
└─include
└─google
└─protobuf
│ any.proto
│ api.proto
│ descriptor.proto
│ duration.proto
│ empty.proto
│ field_mask.proto
│ source_context.proto
│ struct.proto
│ timestamp.proto
│ type.proto
│ wrappers.proto
│
└─compiler
plugin.proto下载好后将 bin 目录添加到环境变量中,以便可以使用protoc命令,完成后看下版本,能正常输出就说明安装成功
$ protoc --version
libprotoc 25.1下载下来的编译器默认不支持 go 语言,因为 go 语言代码生成是单独的一个可执行文件,其它语言全揉一块了,所以再安装 go 语言插件,用于将protocbuf定义翻译成 go 语言源代码。
$ go install google.golang.org/protobuf/cmd/protoc-gen-go@latest假如还需要生成 gRPC 服务代码,再安装如下插件
$ go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest安装后查看其版本
$ protoc-gen-go-grpc --version
protoc-gen-go-grpc 1.3.0
$ protoc-gen-go --version
protoc-gen-go.exe v1.31.0这些插件也是单独的二进制文件,不过只能通过protoc来调用,不能单独执行。
(this program should be run by protoc, not directly)除此之外还有许多其它插件,比如生成openapi接口文档的插件等等,感兴趣可以自己去搜索。
生成
还是拿之前的例子来讲,结构如下
pb_learn
│ common.proto
│
├─monster
│ monster.proto
│
└─player
health.proto
player.proto对于生成代码来说,总共要指定三个参数
- 扫描路径,指示编译器从哪里寻找
protobuf文件以及如何解析导入路径 - 生成路径,编译好后的文件放在哪里
- 目标文件,指定哪些目标文件要被编译。
在开始之前要确保protobuf文件中的go_package设置正确,通过protoc -h来查看其支持的参数,最常用的是-I或者--proto_path,可以多次使用来指定多个扫描路径,例如
$ protoc --proto_path=./pb_learn --proto_path=./third_party仅仅只是指定扫描路径是不够的,还需要指定生成路径以及目标protobuf文件,这里是生成go文件所以使用--go_out参数,由之前下载的protoc-gen-go插件支持。
$ cd pb_learn
$ protoc --proto_path=. --go_out=. common.proto
$ ls
common.pb.go common.proto monster/ player/--go_out的参数就是指定的生成路径,.表示的就是当前路径,common.proto就是指定要编译的文件。如果要生成grpc代码(前提是装了 grpc 插件),可以加上--go-grpc_out参数(如果protobuf文件中没有定义service,就不会生成对应文件)。
$ protoc --proto_path=. --go_out=. --go-grpc_out=. common.proto
$ ls
common.pb.go common.proto common_grpc.pb.go monster/ player/common.pb.go是生成的protobuf类型定义,common_grpc.pb.go是生成的gRPC代码,它基于前者,如果没有生成对应语言的定义,也就没法生成gRPC代码。
如果想要将该目录下的所有的protobuf文件都编译,可以使用通配符*,比如``
$ protoc --proto_path=. --go_out=.. common.proto --go-grpc_out=. ./*.proto如果想要包含所有的文件,可以使用**通配符,比如./**/*.proto。
$ protoc --proto_path=. --go_out=.. common.proto --go-grpc_out=. ./*.proto但是,这种方法仅适用于支持这种通配符的 shell,比如在 windows 下,cmd 或 powershell 都不支持这种写法
D> protoc --proto_path=. --go_out=.. common.proto --go-grpc_out=. ./**/*.proto
Invalid file name pattern or missing input file "./**/*.proto"幸运的是 gitbash 支持 linux 许多命令,也可以让 windows 支持这种语法。为了避免每次都要写重复的命令,可以将其放在makefile里面
.PHONY: all
proto_gen:
protoc --proto_path=. \
--go_out=paths=source_relative:. \
--go-grpc_out=paths=source_relative:. \
./**/*.proto ./*.proto可以注意到多了一个paths=source_relative:.,这是在设置文件生成的路径模式,总共有以下几个可选项
paths=import,默认就是这个,文件会生成在import所指定的目录下,它也可以是一个模块路径。比如现有一个文件protos/buzz.proto,指定paths=example.com/project/protos/fizz,那么最终会生成example.com/project/protos/fizz/buzz.pb.go。module=$PREFIX,在生成时,会删除路径前缀。在上面的例子中,如果指定前缀example.com/project,那么最终会生成protos/fizz/buzz.pb.go,这个模式主要是用于将其直接生成在模块中(感觉好像没什么区别)。paths=source_relative,生成的文件会在指定目录中保持与protobuf文件相同的相对结构。
冒号:间隔后就是指定的生成路径。
| common.proto
| common.pb.go
│
├─monster
│ monster.pb.go
│ monster.proto
│
└─player
health.pb.go
health.proto
health_grpc.pb.go
player.pb.go
player.proto反射
通过options可以对enum和messagee进行拓展,先导入"google/protobuf/descriptor.proto"
import "google/protobuf/descriptor.proto";
extend google.protobuf.EnumValueOptions {
optional string string_name = 123456789;
}
enum Integer {
INT64 = 0[
(string_name) = "int_64"
];
}这相当于给该枚举值加了一个元信息。对于message也是同理,如下
import "google/protobuf/descriptor.proto";
extend google.protobuf.MessageOptions {
optional string my_option = 51234;
}
message MyMessage {
option (my_option) = "Hello world!";
}这就相当是有关于protobuf的反射,在生成代码后可以通过Descriptor来进行访问,如下
func main() {
message := pb_learn.MyMessage{}
message.ProtoReflect().Descriptor().Options().ProtoReflect().Range(func(descriptor protoreflect.FieldDescriptor, value protoreflect.Value) bool {
fmt.Println(descriptor.FullName(), ":", value)
return true
})
}输出
my_option:"Hello world!"这种方式可以类比一下 go 中给结构体加 tag,都是差不的感觉,根据这种方式还能实现参数校验的功能,只需要在options中书写规则,通过Descriptor来进行检查。